
【超初心者向け】AE(AutoEncoder)をPython(PyTorch)で実装してみる。



今回は,機械学習の分野でベースとなるモデルであるAE(AutoEncoder)をPythonで実装する方法をお伝えしていこうと思います。本記事はpython実践講座シリーズの内容になります。その他の記事は,こちらの「Python入門講座/実践講座まとめ」をご覧ください。

読みたい場所へジャンプ!
AEの概要
AE(オートエンコーダ)とは,簡単にまとめると以下のような手法です。
●入力を潜在空間上の特徴量で表す(エンコーダ)
●潜在空間から元の次元に戻す(デコーダ)
AEは主成分分析の非線形拡張だとも捉えられます。最近では,AEをベースに発展させたモデルが数多く考案されており,AEは機械学習の中でも非常に重要なモデルの1つとなっています。
ネットワークの構造
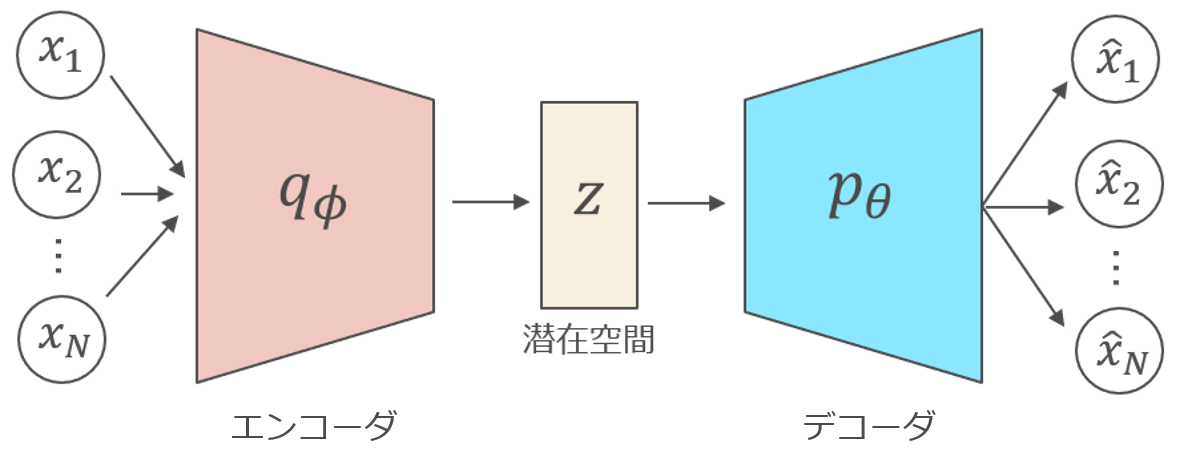 AEのネットワーク構造
AEのネットワーク構造AEのネットワークは「エンコーダ部」と「デコーダ部」に分かれます。
エンコーダでは,基本的に元データの次元よりも小さな次元の潜在空間に入力を変換します。一方,デコーダでは潜在空間から元データの次元まで次元を元に戻します。AEのモチベーションは,再構成された$\hat{x}$が元データ$x$とできるだけ「近く」なるようにネットワークを学習させていくというものです。ですので,目的関数は再構成誤差($\hat{x}$と$x$の二乗誤差など)が用いられます。
データセットの準備
今回は,コチラの記事でお伝えしている異常音検知用のデータセット「ToyADMOS」を利用したいと思います。音響特徴量としては,メルスペクトログラムの64次元を利用したいと思います。コチラの記事でお伝えしているwavファイルからメルスペクトログラムを学習データ分並べる方法を利用します。
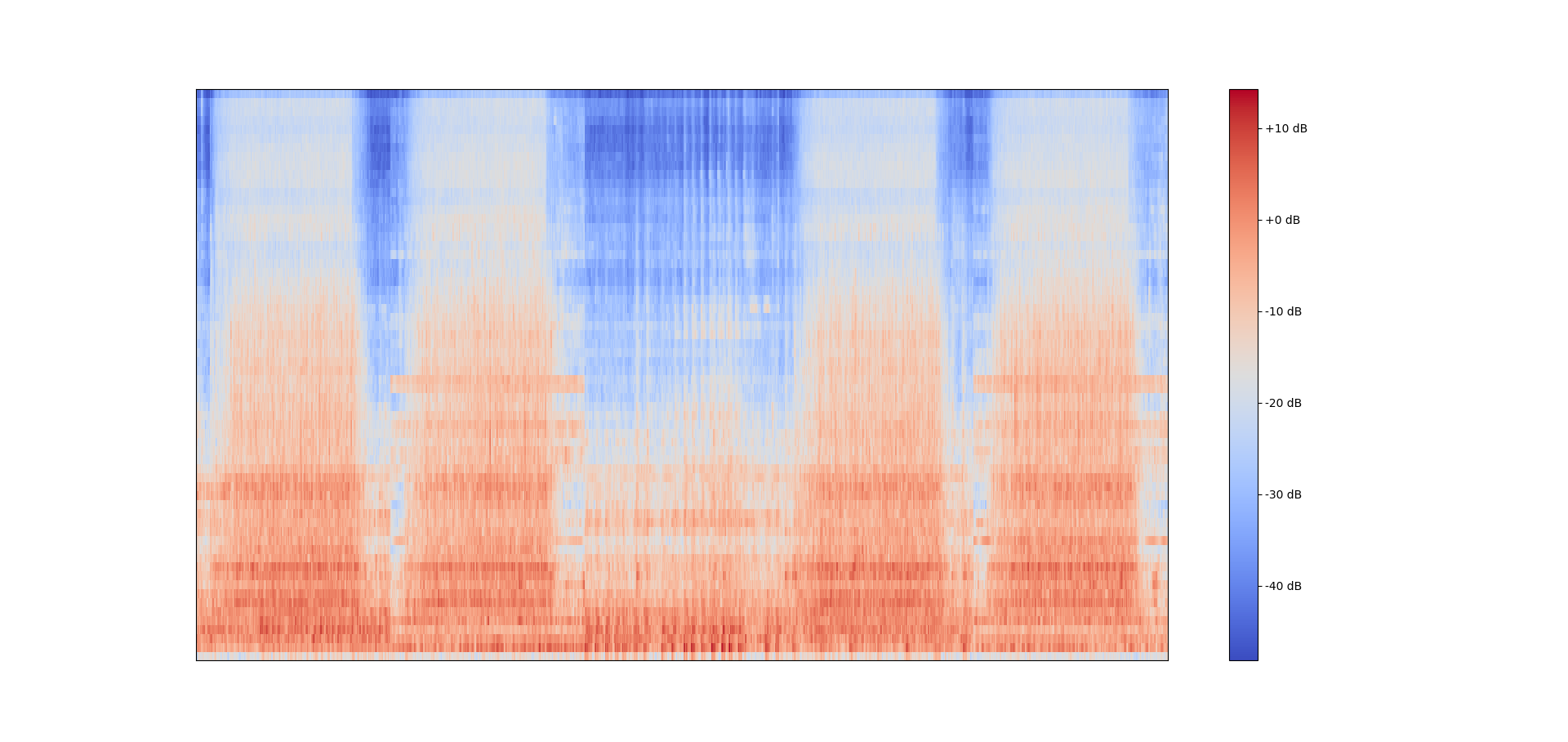 ToyTrainの先頭5つのwavファイルをタイムフレーム方向に並べたメル周波数スぺクトログラム
ToyTrainの先頭5つのwavファイルをタイムフレーム方向に並べたメル周波数スぺクトログラムimport os
import sys
import numpy as np
import librosa
import glob
##############################################################
'''
ここから別記事(https://tips-memo.com/python-mel)で解説済み
'''
##############################################################
def extract_mel(wav, sr, n_mels=64): #(timeframe, mel_dim)
audio, _ = librosa.load(wav, sr=sr)
mel = librosa.feature.melspectrogram(y=audio, sr=sr, n_mels=n_mels).T
return mel
def data_list(path, sr, n_mels=64):
wav_list = glob.glob(path)
size = len(wav_list)
data = np.ones((1, n_mels))
count= 0
for wavname in wav_list:
component = extract_mel(wavname, sr=sr, n_mels=64)
data = np.concatenate([data, component], axis=0)
count += 1
sys.stdout.write("\r%s" % "現在"+str(np.around((count/len(wav_list))*100 , 2))+"%完了")
sys.stdout.flush()
return data[1:], size
##############################################################
'''
ここまで別記事(https://tips-memo.com/python-mel)で解説済み
'''
##############################################################
Toytype = "ToyCar"
name = "exp1_dataset_" + Toytype
# pathの設定
train_wav_path= "./ToyADMOS-dataset-master/{}/train_normal/*".format(name)
test_normal_wav_path = "./ToyADMOS-dataset-master/{}/test_normal/*".format(name)
test_anomaly_wav_path = "./ToyADMOS-dataset-master/{}/test_anomaly/*".format(name)
# パラメータの保存先指定
out_audio_dir = "../data/audio/ToyADMOS/{}".format(Toytype)
if not os.path.exists(out_audio_dir):
os.makedirs(out_audio_dir)
# wavデータの一括読み込み
# 今回はメル周波数スペクトログラムを16000Hz, 64次元取得して全データに関して縦に並べている
print("---read_training_wav---")
train_data_list, size_train = my_modules.data_list(train_wav_path, sr=16000, n_fft=512, hop_length=160, n_mels=64)
print("\n---read_test_normal_wav---")
test_normal_data_list, size_test_normal = my_modules.data_list(test_normal_wav_path, sr=16000, n_fft=512, hop_length=160, n_mels=64)
print("\n---read_test_anomaly_wav---")
test_anomaly_data_list, size_test_anomaly = my_modules.data_list(test_anomaly_wav_path, sr=16000, n_fft=512, hop_length=160, n_mels=64)
print("\n")
# メル周波数スペクトログラムの保存
np.save('./{}/mel/train_mel_16000Hz_64dim.npy'.format(out_audio_dir), train_data_list)
np.save('./{}/mel/test_normal_mel_16000Hz_64dim.npy'.format(out_audio_dir), test_normal_data_list)
np.save('./{}/mel/test_anomaly_mel_16000Hz_64dim.npy'.format(out_audio_dir), test_anomaly_data_list)
# サイズの保存
np.save('./{}/size/size_train.npy'.format(out_audio_dir), np.array([size_train]))
np.save('./{}/size/size_test_normal.npy'.format(out_audio_dir), np.array([size_test_normal]))
np.save('./{}/size/size_test_anomaly.npy'.format(out_audio_dir), np.array([size_test_anomaly]))以下でディレクトリ構成を説明しますが「../data/audio/ToyADMOS」に作成したスペクトログラムとそのサイズをndarray型で保存しています。サンプリング周波数が16000Hzのときに短時間フーリエ変換のホップ幅「hop_length」を160サンプルにすることで,1サンプルは0.01[s]になります。
\begin{eqnarray}
t_{sample} &=& \frac{l_{hop}}{f_{sample}}\\
&=& \frac{160}{16000}\\
&=& 0.01
\end{eqnarray}
実装
実装に関しては,非常に単純な構造になっています。ここでは,以下のようなディレクトリ構成を想定しています。カレントディレクトリは「algorithm」です。
必要なライブラリのインポート
import os
import numpy as np
import torch
import torchvision
from torch import nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import transforms
from torch.optim.lr_scheduler import LambdaLR
import matplotlib.pyplot as plt必要なライブラリをインポートします。LambdaLPは学習率の変化を自分で記述するためのライブラリです。
deviceの定義
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")もしGPUが使えるなら,使えるようにdeviceを定義しておきましょう。
データの保存先・読み込み先の指定
model_name = "AE"
dataset_type = "ToyADMOS"
Toy_type = "ToyCar" #"ToyCar" ot "ToyConveyor" or "ToyTrain"
out_params_dir = "../data/models/{}/params/{}/{}".format(model_name, dataset_type, Toy_type)
out_figs_dir = "../data/models/{}/images/{}/{}".format(model_name, dataset_type,Toy_type)
out_texts_dir = "../data/models/{}/texts/{}/{}".format(model_name,dataset_type,Toy_type)
in_audio_dir = "../data/audio/{}/{}".format(dataset_type,Toy_type)
if not os.path.exists(out_params_dir):
os.makedirs(out_params_dir)
if not os.path.exists(out_figs_dir):
os.makedirs(out_figs_dir)
if not os.path.exists(out_texts_dir):
os.makedirs(out_texts_dir)
if not os.path.exists(in_audio_dir):
os.makedirs(in_audio_dir)これからAEを発展させることを考えて,汎用的な指定の仕方をしています。「os.makedirs」では末端ディレクトリが存在しない場合も勝手に作成してくれます。
データセットのロード
# データのロード
train_data_list = np.load('./{}/mel/train_mel_16000Hz_64dim.npy'.format(in_audio_dir))
# データのサイズを取得・表示
size_train = np.load('./{}/size/size_train.npy'.format(in_audio_dir))[0]
print("\n訓練用データサイズ:"+str(size_train))audio以下に先ほど作成したデータセットのメル周波数スペクトログラムが入っていることを前提としてデータを読み込んでサイズを表示しています。
マイデータセットの定義
from torch.utils.data import Dataset
# ExpandDatasetは1つの時間フレームに対して前後10フレームを取得するようなデータセット
class ExpandDataset(Dataset):
def __init__(self, data, transform=None):
self.transform = transform
self.data = data
self.data_num = len(data)
if self.data.ndim==2:
self.pad_data_fr = data[:10][::-1]
self.pad_data_bc = data[-10:][::-1]
self.pad_data = np.concatenate([self.pad_data_fr, data, self.pad_data_bc], axis=0)
elif self.data.ndim==3:
self.pad_data_fr = data[:,:10,:][:,::-1,:]
self.pad_data_bc = data[:,-10:,:][:,::-1,:]
self.pad_data = np.concatenate([self.pad_data_fr, data, self.pad_data_bc], axis=1)
def __len__(self):
return self.data_num
def __getitem__(self, idx):
if self.transform:
if self.data.ndim==2:
out_data = self.transform(self.pad_data)[0][idx:idx+20].flatten()
elif self.data.ndim==3:
index = int(random.uniform(0,self.data.shape[1]))
out_data = self.transform(self.pad_data)[:,idx, index:index+20].flatten()
else:
print("transformを使用しテンソル化してください")
return out_datapytorchで自作データセットを扱う場合には,自分でデータセットのクラスを定義しなくてはなりません。詳しくはコチラの記事でお伝えしていますが,特徴量の抽出方法も自分のデータセットクラスを定義する際に決めることができます。今回は,pytorchのデータローダーで指定されたインデックスの前後10フレームを取ってくるようなデータセットを定義しました。
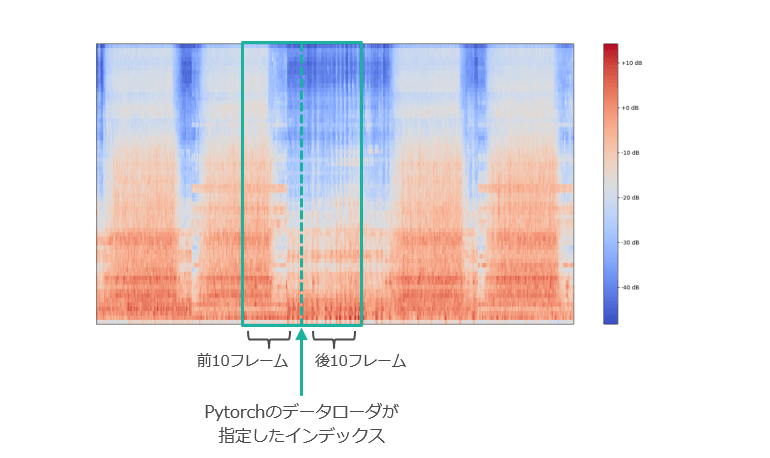 描画するときはスペクトログラムを転置しています。
描画するときはスペクトログラムを転置しています。ネットワークの定義
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
self.dense_enc1 = nn.Linear(1280, 512)
self.bn1 = nn.BatchNorm1d(512)
self.dense_enc2 = nn.Linear(512, 256)
self.bn2 = nn.BatchNorm1d(256)
self.dense_enc3 = nn.Linear(256,128)
self.dense_dec1 = nn.Linear(128,256)
self.bn4 = nn.BatchNorm1d(256)
self.dense_dec2 = nn.Linear(256, 512)
self.bn5 = nn.BatchNorm1d(512)
self.drop1 = nn.Dropout(p=0.2)
self.dense_dec3 = nn.Linear(512, 1280)
def encoder(self, x):
x = F.relu(self.dense_enc1(x))
x = self.bn1(x)
x = F.relu(self.dense_enc2(x))
x = self.bn2(x)
x = self.dense_enc3(x)
return x
def decoder(self, x):
x = F.relu(self.dense_dec1(x))
x = self.bn4(x)
x = F.relu(self.dense_dec2(x))
x = self.bn5(x)
x = self.drop1(x)
x = self.dense_dec3(x)
return x
def forward(self, x):
z = self.encoder(x)
x = self.decoder(z)
return x, zいよいよネットワークの定義です。何点かポイントがあります。まずは,入力の次元数が1280であるという点に注意しましょう。
先ほど指定されたインデックスの前後10フレームを取ってくるようなデータセットクラスを定義しましたね。そして,もともとスペクトログラムの周波数分解能(周波数方向の次元数)は64で指定していましたので,データセットクラス内で一次元化(flatten)された特徴量は20×64=1280次元になるのです。
 描画するときはスペクトログラムを転置しています
描画するときはスペクトログラムを転置していますデータセットのインスタンス化
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = my_dataset.ExpandDataset(train_data_list, transform)とりあえず,今回の前処理はテンソル化するだけにしておきます。他に考えられる処理としては,極端に小さい値は除算時にオーバーフローを起こしてしまう可能性があるため,0にしてしまうなどの操作が考えられます。
データセットをデータローダに変換
train_batch_size = 100
train_loader = DataLoader(train_dataset, batch_size=train_batch_size, shuffle=True)バッチサイズは適当に与えています。
モデルのインスタンス化
num_epochs = 200
learning_rate = 1e-4
model = Autoencoder().to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=1e-4)モデルをインスタンス化してGPUに突っ込みます。誤差基準は二乗誤差を使用します。optimizerにはアダムを利用して,学習率の初期値は$10^{-4}$とします。
学習率の変化を設定
def func_100(epoch):
if epoch <= 100:
return 1
elif 100 < epoch:
return -0.99*(1e-2)*(epoch) + 1.99scheduler = LambdaLR(optimizer, lr_lambda=my_scheduler.func_100)学習率をエポック数に対して変化させる関数を記述します。今回は,エポック数を200と固定して考えます。初期値を$10^{-4}$としたときに,エポック数が100までは学習率を変えず,100を超えてからエポック数が200のときに学習率が$10^{-6}$となるように変化させていきます。この変化率は,原著論文[1]に従っています。
モデルの学習
model.train()
loss_list = []
for epoch in range(num_epochs):
losses = []
for x in train_loader:
x = x.to(device)
model.zero_grad()
y, z = model(x.float())
loss = criterion(y.float(), x.float())
loss.backward()
optimizer.step()
losses.append(loss.cpu().detach().numpy())
print('epoch [{}/{}], loss: {:.4f}'.format(epoch + 1, num_epochs, np.average(losses)))
scheduler.step()
loss_list.append(np.average(losses))ここはいつもの流れです。一点だけ注意するべきなのは,各エポックごとに「scheduler.step」を組み込む点です。
モデルの保存
name_loss = "train_loss_"+str(model_name)+"_"+str(feature_type)+".npy"
name_params = "params_"+str(model_name)+"_"+str(feature_type)+".pth"
name_graph = "train_loss_"+str(model_name)+"_"+str(feature_type)+".png"
np.save("./{}/{}".format(out_params_dir, name_loss), np.array(loss_list))
torch.save(model.state_dict(), './{}/{}'.format(out_params_dir, name_params))今回は,比較的大規模なデータセットを扱っているため,しっかりとモデルを保存するようにしましょう。paramsディレクトリに保存するように指定しています。
グラフ描写
plt.figure()
plt.plot(range(epoch), loss_list[1:], 'r-', label='train_loss')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.grid()
plt.savefig('./{}/{}'.format(out_figs_dir, name_graph))
plt.close()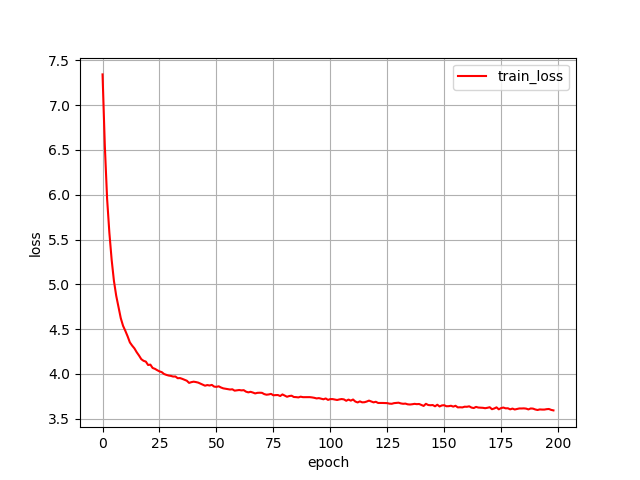 ToyCarのloss減少過程
ToyCarのloss減少過程初回のlossはランダムに出力された未学習の値であるため,描画していません。しっかりと学習できていることが分かります。
評価
# データの保存先と読み込み先の指定
name_roc = "roc_curve_"+str(model_name)+"_"+str(feature_type)+".png"
name_y_true = "y_true_" +str(model_name)+"_"+str(feature_type)
name_y_score = "y_score_" +str(model_name)+"_"+str(feature_type)
# テストデータの読み込み
test_normal_data_list = np.load('./{}/mel/test_normal_mel_16000Hz_64dim.npy'.format(in_audio_dir))
test_anomaly_data_list = np.load('./{}/mel/test_anomaly_mel_16000Hz_64dim.npy'.format(in_audio_dir))
# データサイズの出力
size_test_normal = np.load('./{}/size/size_test_normal.npy'.format(in_audio_dir))[0]
size_test_anomaly = np.load('./{}/size/size_test_anomaly.npy'.format(in_audio_dir))[0]
print("\n正常音テストデータサイズ:"+str(size_test_normal))
print("異常音テストデータサイズ:"+str(size_test_anomaly))
# バッチサイズの指定
# ここではデータサイズの約数になるように定めています
test_normal_batch_size = 70
test_anomaly_batch_size = 66
# データセットの準備
transform = transforms.Compose([transforms.ToTensor()])
test_normal_dataset = my_dataset.ExpandDataset(test_normal_data_list, transform)
test_anomaly_dataset = my_dataset.ExpandDataset(test_anomaly_data_list, transform)
test_normal_loader = DataLoader(test_normal_dataset, batch_size=test_normal_batch_size, shuffle=False)
test_anomaly_loader = DataLoader(test_anomaly_dataset, batch_size=test_anomaly_batch_size, shuffle=False)
# テスト開始
model = model.to(device)
params = torch.load('./{}/{}'.format(out_params_dir, name_params))
model.load_state_dict(params)
model.eval()
# lossを1フレームごとに算出するためにcriterionを再設定
criterion = nn.MSELoss(reduction="none")
# 正常データテスト
losses_normal = []
count=0
for x in test_normal_loader:
x = x.to(device)
y, z = model(x.float())
loss_normal = criterion(y.float(), x.float())
losses_normal.append(loss_normal.cpu().detach().numpy())
sys.stdout.write("\r%s" % "現在"+str(np.around((count/len(test_normal_loader))*100 , 2))+"%完了")
sys.stdout.flush()
count += 1
# 異常スコアの計算
# まずは1280の方向に平均を取って一次元化する
output_normal = np.mean(np.array(losses_normal), axis=2).flatten()
# wavファイルごとに分割する
output_normal_split = np.array(np.split(output_normal, size_test_normal))
# 最初と最後の50フレームを削除する
# 理由はINDファイルを利用しており,最初と最後には合成した背景雑音しか含まれていないため
output_normal_split_cut = output_normal_split[:,50:-50]
# 各wavファイルごとに異常度の最大値をスコアとして採用する
output_normal_max = output_normal_split_cut.max(axis=1)
# 異常データテスト
losses_anomaly = []
count=0
for x in test_anomaly_loader:
x = x.to(device)
y, z = model(x.float())
loss_anomaly = criterion(y.float(), x.float())
losses_anomaly.append(loss_anomaly.cpu().detach().numpy())
sys.stdout.write("\r%s" % "現在"+str(np.around((count/len(test_anomaly_loader))*100 , 2))+"%完了")
sys.stdout.flush()
count += 1
# 異常スコアの計算
# まずは1280の方向に平均を取って一次元化する
output_anomaly = np.mean(np.array(losses_anomaly), axis=2).flatten()
# wavファイルごとに分割する
output_anomaly_split = np.array(np.split(output_anomaly, size_test_anomaly))
# 最初と最後の50フレームを削除する
# 理由はINDファイルを利用しており,最初と最後には合成した背景雑音しか含まれていないため
output_anomaly_split_cut = output_anomaly_split[:,50:-50]
# 各wavファイルごとに異常度の最大値をスコアとして採用する
output_anomaly_max = output_anomaly_split_cut.max(axis=1)
# ROC曲線の描画
y_true = np.concatenate([np.zeros(size_test_normal), np.ones(size_test_anomaly)])
y_score = np.concatenate([output_normal_max, output_anomaly_max])
np.save("./{}/{}".format(out_params_dir, name_y_true), y_true)
np.save("./{}/{}".format(out_params_dir, name_y_score), y_score)
fpr, tpr, thresholds = metrics.roc_curve(y_true, y_score)
auc = metrics.auc(fpr, tpr)
plt.plot(fpr, tpr, label='ROC curve (area = %.2f)'%auc)
plt.legend()
plt.xlabel('FPR: False positive rate')
plt.ylabel('TPR: True positive rate')
plt.grid()
plt.savefig("./{}/{}".format(out_figs_dir, name_roc))
plt.close()
# F値の計算
# FPRを0.1に抑えた時の閾値を採用する
upper_fpr = 0.1
fpr_index = np.argmin(np.abs(fpr - upper_fpr))
gap = y_score - thresholds[fpr_index]
y_pred = (gap>0)*1
f_score = f1_score(y_true, y_pred)
thres = thresholds[fpr_index]
print("F-score under fpr=0.1:"+str(f_score))
print("thresholds under fpr=0.1:"+str(thres))Out:
F-score_under_fpr=0.1:0.7927565392354124
Threshold:2.8711948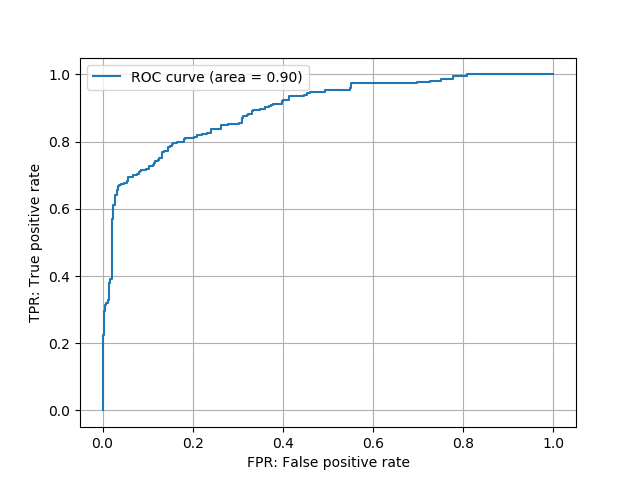 ToyCarのROC曲線
ToyCarのROC曲線今回は「正常 or 異常」の二値分類タスクであるため,評価指標はROC曲線と下側面積AUCを利用します。詳しくは,コチラの記事でROC曲線について説明しています。
細かいことはコメントで記してあります。今回利用したファイルはToyADMOSデータセットの中でもINDタイプであったため,各wavファイルの先頭と末尾は合成した背景雑音しか含まれていません。そのため,恣意的な操作ではありますが,前後50フレームはカットした形で異常スコアを計算します。
また,F値に関しては閾値を設定しなければ求めることができません。そこで,今回は原著論文[1]に従って,FPRを0.1に抑えたときの閾値を利用することにしました。
まとめ
ToyADMOSデータセットを利用したオートエンコーダの実装を確認しました。実際に実験を行うと,機械学習の大半は前処理やデータセット整備にかかっているということが身に染みて感じられました。おもちゃではありますが,現状では不足している異常音検知タスクのデータセットを作成していただいたNTT研究所に感謝です。
[1] Koizumi, Yuma, et al. “ToyADMOS: A Dataset of Miniature-Machine Operating Sounds for Anomalous Sound Detection.” arXiv preprint arXiv:1908.03299 (2019).














初めまして。初歩的な質問となり大変申し訳ないのですが、
項目「データセットの準備」の52行目のmy_modulesという関数はどこで定義していますでしょうか。
お忙しいところ恐れ入りますがご教授いただければ幸いです。
なー様
ご質問ありがとうございます。かなり昔の記事で未熟すぎる部分が多く恐縮なのですが、17行目で定義されているdata_listをそのまま呼び出せばよさそうです。
ご回答ありがとうございます。
ご確認頂き誠にありがとうございました。
内容確認させて頂きます!