
【超初心者向け】ド素人がPyTorchで自作データセットを作るまで。



今回は,既成のデータセット(MNIST,CIFAR)の代わりに自分のデータセットを作って利用する方法をお伝えしていこうと思います。内容としては,つい1週間ほど前まではPyTorchなど触ったこともなかった私が,MINSTを卒業して自作データセットを利用し始めるまでの(苦難の)道のりを記録したものです。
本記事はpython実践講座シリーズの内容になります。その他の記事は,こちらの「Python入門講座/実践講座まとめ」をご覧ください。
結論から
まずは結論からお伝えした方が早いと思います。私が試行錯誤して得たエッセンスは,以下の内容になります。
【少しおかたい言葉で…】
●PyTorchで自作データセットを利用するためにはtransforms/Dataset/DataLoaderを定義する必要がある。
●transformsはデータの前処理を記述するモジュール
●Datasetはデータをtransformsしてラベルと合わせて返すモジュール
●DataLoaderは学習のためにデータをバッチサイズに分割してイテレータを返すモジュール

となりますよね。そこで,より分かりやすくするために噛み砕いてエッセンスを説明してみます。
【より簡単な言葉で…】
●PyTorchで自作データセットを使うのは少し大変。
●だって,自分でクラスを作らなきゃいけないから。
●でも,エラい人がクラスの枠組みは作ってくれいているから大丈夫。
●その枠組みっていうのは「前処理」「ラベル付け」「分割」
●自分で決めなくてはいけないのは「前処理の方法」「ラベルの設定」くらい
●あとは細々したものを設定すればOK。
こんな感じです。要するに,使いたいデータを「適切な値」をとる「テンソル型」に変形して「ラベル」と組み合わせて「イテレータ」として出力する,という流れがPyTorchで自作データセットを利用するための流れになります。ちなみに,イテレータとは簡単に言えば繰り返しを指定するために使われるモノです。
for i in range(5): #range(5)がイテレータ
print(i)out:
0
1
2
3
4
この記事の出どころ
PyTorchの公式チュートリアルでも,実はデータセットの作り方は解説しています。今回も今まで同様にチュートリアルを噛み砕いてもよかったのですが,具体例が少し難しすぎるのと,コードも長いので,今回はエッセンスを絞ってお伝えしていこうと思っています。
PyTorch公式チュートリアル:「DATA LOADING AND PROCESSING TUTORIAL」
既成データセットを観察
なにごとも,まずはお手本を真似ることから始まります。データセットのお手本といえば,MNISTでしょう。そこで,PyTorchでMNISTを利用する場合に使用する「transforms」「Dataset」「DataLoader」について観察していきたいと思います。
ますは読み込み
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: x.view(-1))])
dataset_train = datasets.MNIST(
root='~/mnist',
train=True,
download=True,
transform=transform)
dataset_valid = datasets.MNIST(
root='~/mnist',
train=False,
download=True,
transform=transform)
dataloader_train = utils.data.DataLoader(dataset_train,
batch_size=1000,
shuffle=True)
dataloader_valid = utils.data.DataLoader(dataset_valid,
batch_size=1000,
shuffle=True)

となりますよね。ここは一旦我慢してもらって,完成品を観察していきたいと思います。あとでしっかり説明します。
前処理
まずは,transformから見てみましょう。
print(transform)out:
Compose(
ToTensor()
Lambda()
)んん?この「transform」は前処理を行う関数のカタマリを表しているみたいですね。「ToTensor」というのはデータセットをテンソル化する関数,「Lambda」というのは「view(-1)」を表す自作関数で,データセットを一次元配列化する役割を担っています。
print(type(transform))out:
<class 'torchvision.transforms.transforms.Compose'>transformは前処理を定義するクラスのインスタンスであることが分かります(設計図から生成されたモノ)。それでは,実際に簡単な二次元配列を渡してみて,一次元配列化されたテンソルが返ってくるか実験してみましょう。
a = np.array([[1,2],[3,4]])
print(transform(a))tensor([1, 2, 3, 4])見事!一次元配列化されたテンソルが返ってきました。注意点としては,渡してあげる配列はNumpy(もしくはPIL Image)でないと怒られてしまいます。次に,datasetを見てみましょう。
データセット
print(dataset_train)Dataset MNIST
Number of datapoints: 60000
Root location: /root/mnist
Split: Trainんん?これはどういうことなんでしょう。出力してみたら設定内容が表示されました。データの個数,ダウンロード先,訓練用ということが書いてあるようです。
print(type(dataset_train))<class 'torchvision.datasets.mnist.MNIST'>なるほど。Pytorchにデフォルトで入ってるMNISTデータセットのオブジェクトなので,出力するだけで設定内容が表示されるように上手く定義されていたのですね。PytorchのDatasetには「インデックスの指定」「長さの取得」が最低限定義されているようなので,実際に試してみましょう。
print(dataset_train[10])
print(len(dataset_train))(tensor([0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.1647, 0.4627, 0.8588,
0.6510, 0.4627, 0.4627, 0.0235, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.4039, 0.9490, 0.9961,
0.9961, 0.9961, 0.9961, 0.9961, 0.2588, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0706, 0.9098,
0.9961, 0.9961, 0.9961, 0.9961, 0.9961, 0.9333, 0.2745, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.4078, 0.9569, 0.9961, 0.8784, 0.9961, 0.9961, 0.9961, 0.5529, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.8118, 0.9961, 0.8235, 0.9961, 0.9961, 0.9961, 0.1333,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.3294, 0.8078, 0.9961, 0.9961, 0.9961, 0.9961,
0.1608, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0941, 0.8196, 0.9961, 0.9961,
0.9961, 0.6706, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.3569, 0.5373, 0.9922, 0.9961,
0.9961, 0.9961, 0.4392, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.1569, 0.8392, 0.9804, 0.9961, 0.9961,
0.9961, 0.9961, 0.9961, 0.1333, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.3176, 0.9686, 0.9961, 0.9961,
0.9961, 0.9961, 0.9961, 0.9961, 0.5725, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.4314, 0.9647,
0.9961, 0.9961, 0.9961, 0.9961, 0.9961, 0.6706, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.2863, 0.3490, 0.3490, 0.3647, 0.9412, 0.9961, 0.6706, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0039, 0.5020, 0.9961, 0.8588, 0.1216,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0275, 0.9961, 0.9961, 0.8392,
0.1098, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.5412, 0.9961, 0.9961,
0.4549, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0745, 0.6941,
0.3529, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0980, 0.9412, 0.9961,
0.9961, 0.1333, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.6431,
0.9961, 0.8431, 0.2471, 0.1412, 0.0000, 0.2000, 0.3490, 0.8078, 0.9961,
0.9961, 0.5451, 0.0314, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.2235, 0.7725, 0.9961, 0.9961, 0.8706, 0.7059, 0.9451, 0.9961, 0.9961,
0.9922, 0.8353, 0.0431, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.5490, 0.4118, 0.9961, 0.9961, 0.9961, 0.9961, 0.9961,
0.9961, 0.9255, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0275, 0.4588, 0.4588, 0.6471, 0.9961,
0.9961, 0.9373, 0.1961, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000]), 3)
60000出ました!インデックス10の一次元化された画像データとそのラベル,そして長さ(データの個数)が60000という内容が表示されました。
訓練用データセット
続いて,dataloaderを見ていきましょう。
print(dataloader_train)<torch.utils.data.dataloader.DataLoader object at 0x7f0598ab97f0>定義した「dataloader」は「DataLoader」オブジェクトとして定められていることが分かります。このオブジェクトですが,「dataset」と同じようにインデックスを指定することができません。
print(dataloader_train[10])TypeError: 'DataLoader' object does not support indexing
しかし,長さを取得することはできます。
print(len(dataloader_train))60なぜ長さは60なのでしょうか。これは,バッチサイズを1000で指定しているからですね。データセットが60000の長さで,1000ごとに分割すれば,60のカタマリができます。さらに,「dataloader」はイテレータなんです。試しに,for分で回してみましょう。長さは60もありますので,とりあえず1つ目のカタマリだけ観察してみます。
for i in dataloader_train:
print(i[0])out:
[tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]), tensor([8, 6, 3, 7, 7, 7, 8, 3, 2, 1, 6, 0, 3, 9, 6, 6, 0, 4, 8, 7, 3, 8, 0, 0,
8, 0, 4, 7, 6, 5, 0, 1, 3, 7, 6, 2, 0, 4, 2, 9, 3, 8, 9, 8, 1, 1, 0, 9,
1, 9, 7, 9, 1, 1, 0, 1, 9, 7, 0, 7, 2, 3, 2, 7, 7, 9, 4, 0, 0, 1, 0, 5,
7, 8, 0, 3, 6, 3, 2, 7, 5, 2, 5, 4, 6, 1, 6, 6, 2, 2, 2, 3, 3, 0, 2, 3,
4, 5, 7, 5, 8, 3, 0, 9, 6, 1, 2, 0, 7, 7, 4, 0, 7, 3, 9, 2, 0, 7, 1, 4,
9, 5, 3, 5, 1, 6, 2, 2, 4, 8, 4, 5, 1, 0, 9, 0, 7, 8, 0, 5, 7, 4, 2, 6,
1, 5, 5, 4, 5, 5, 3, 5, 0, 8, 6, 3, 6, 0, 3, 9, 0, 7, 9, 4, 6, 5, 7, 7,
2, 3, 0, 8, 5, 0, 3, 0, 2, 9, 6, 4, 5, 4, 5, 0, 7, 7, 7, 3, 8, 3, 7, 1,
8, 9, 5, 3, 2, 9, 1, 5, 3, 9, 4, 5, 9, 3, 4, 0, 8, 1, 3, 8, 3, 3, 2, 8,
6, 2, 4, 1, 1, 8, 7, 5, 8, 7, 3, 1, 5, 1, 5, 4, 7, 5, 5, 9, 4, 2, 5, 4,
7, 7, 6, 3, 8, 3, 8, 0, 1, 3, 7, 8, 4, 8, 7, 5, 3, 3, 9, 3, 4, 4, 6, 0,
6, 1, 6, 2, 0, 0, 0, 4, 2, 0, 4, 8, 1, 6, 5, 7, 3, 6, 5, 8, 8, 9, 7, 7,
5, 8, 2, 5, 2, 2, 6, 7, 1, 1, 2, 5, 4, 9, 6, 4, 3, 2, 6, 7, 2, 6, 3, 2,
7, 6, 7, 6, 8, 8, 3, 6, 5, 5, 4, 5, 4, 3, 1, 0, 1, 6, 2, 3, 7, 7, 7, 9,
7, 6, 3, 9, 6, 2, 2, 2, 2, 4, 1, 0, 5, 1, 7, 9, 0, 8, 3, 1, 3, 1, 8, 1,
5, 9, 1, 4, 7, 8, 7, 1, 7, 3, 7, 6, 8, 6, 1, 3, 4, 2, 8, 1, 7, 6, 7, 4,
9, 7, 2, 3, 3, 3, 0, 5, 5, 8, 6, 0, 8, 6, 8, 3, 6, 8, 2, 3, 0, 9, 6, 2,
7, 2, 3, 8, 8, 8, 8, 8, 4, 1, 1, 7, 2, 2, 2, 1, 8, 3, 1, 0, 5, 4, 4, 7,
9, 5, 9, 7, 9, 2, 7, 8, 2, 1, 9, 0, 0, 0, 5, 9, 5, 7, 1, 3, 2, 4, 6, 9,
9, 9, 6, 0, 0, 1, 4, 0, 2, 1, 8, 0, 1, 7, 1, 3, 0, 2, 4, 8, 1, 9, 0, 1,
4, 2, 2, 3, 2, 6, 4, 2, 0, 6, 7, 1, 9, 1, 3, 1, 2, 0, 8, 9, 6, 7, 6, 8,
0, 4, 0, 5, 5, 5, 2, 7, 7, 5, 5, 9, 2, 4, 4, 9, 4, 7, 4, 8, 2, 4, 3, 0,
5, 1, 1, 3, 8, 9, 8, 1, 3, 6, 5, 3, 0, 3, 7, 1, 1, 3, 6, 2, 7, 1, 0, 2,
7, 3, 8, 1, 6, 6, 7, 5, 6, 8, 5, 1, 9, 5, 7, 8, 5, 3, 2, 9, 5, 3, 7, 8,
0, 1, 3, 3, 4, 0, 3, 6, 6, 8, 0, 7, 3, 7, 0, 8, 0, 4, 5, 9, 0, 7, 9, 7,
2, 9, 3, 2, 1, 1, 8, 3, 8, 0, 1, 7, 6, 1, 9, 3, 1, 3, 8, 4, 5, 8, 3, 3,
0, 4, 0, 3, 4, 5, 5, 7, 7, 9, 8, 1, 1, 4, 9, 8, 5, 6, 2, 1, 1, 9, 5, 2,
7, 5, 0, 6, 4, 3, 7, 9, 8, 2, 9, 6, 2, 6, 1, 5, 0, 5, 9, 4, 6, 4, 8, 5,
5, 7, 1, 0, 9, 9, 2, 7, 2, 8, 2, 2, 6, 3, 9, 0, 3, 6, 0, 7, 3, 0, 3, 0,
5, 3, 8, 3, 3, 1, 0, 6, 0, 1, 7, 7, 6, 1, 3, 3, 7, 5, 7, 2, 9, 6, 7, 2,
2, 1, 0, 7, 8, 7, 9, 8, 6, 2, 2, 3, 1, 7, 3, 1, 1, 0, 7, 4, 7, 1, 8, 0,
4, 4, 2, 4, 7, 3, 4, 8, 6, 9, 5, 8, 9, 3, 7, 2, 5, 2, 0, 2, 9, 0, 9, 3,
2, 9, 2, 2, 0, 1, 4, 5, 3, 8, 5, 4, 9, 8, 7, 4, 6, 8, 6, 8, 8, 9, 0, 0,
3, 5, 2, 8, 7, 0, 2, 9, 1, 6, 1, 1, 0, 6, 3, 7, 9, 1, 7, 7, 1, 9, 9, 8,
1, 8, 1, 6, 3, 3, 2, 2, 5, 3, 4, 9, 1, 8, 8, 9, 5, 0, 4, 3, 2, 6, 4, 5,
9, 5, 1, 3, 5, 9, 4, 9, 3, 5, 9, 3, 7, 7, 8, 4, 5, 1, 5, 9, 9, 7, 2, 5,
7, 2, 6, 8, 7, 1, 2, 0, 6, 1, 0, 9, 2, 2, 9, 9, 0, 2, 7, 1, 6, 3, 6, 0,
1, 7, 9, 0, 2, 9, 6, 2, 3, 3, 3, 9, 1, 9, 7, 6, 6, 0, 1, 3, 8, 7, 9, 7,
2, 4, 9, 9, 4, 1, 7, 5, 0, 7, 2, 5, 4, 9, 3, 9, 5, 1, 1, 5, 2, 5, 7, 5,
7, 6, 2, 2, 0, 1, 9, 0, 6, 6, 8, 2, 3, 0, 7, 5, 9, 1, 5, 8, 4, 4, 5, 7,
7, 2, 8, 3, 1, 5, 7, 8, 3, 2, 7, 1, 2, 0, 0, 6, 4, 6, 5, 6, 9, 9, 1, 4,
6, 6, 1, 1, 5, 9, 9, 4, 8, 9, 1, 2, 9, 7, 1, 1])]前半は1000個のデータ,後半はそのラベルを表しています。しっかりとイテレータの働きをしていますね。
ここまでで,自作データセットで定義しなくてはならない三要素に関して観察を加えました。それでは,以下では実際に自作データセットを用意していきましょう。
自作データセットの作成
今回は,超簡単に「長さ10で同じ数字が格納されたリスト」をデータセットとします。数字は0から9までの10個を用いることにします。テンソル化するときにNumpyである必要があるため,今回は「numpy.ndarray」で定義します。
data = np.array([np.array([0 for i in range(10)]),
np.array([1 for i in range(10)]),
np.array([2 for i in range(10)]),
np.array([3 for i in range(10)]),
np.array([4 for i in range(10)]),
np.array([5 for i in range(10)]),
np.array([6 for i in range(10)]),
np.array([7 for i in range(10)]),
np.array([8 for i in range(10)]),
np.array([9 for i in range(10)])])
label = np.array([i for i in range(10)])
print(data)
print(label)out:
[[0 0 0 0 0 0 0 0 0 0]
[1 1 1 1 1 1 1 1 1 1]
[2 2 2 2 2 2 2 2 2 2]
[3 3 3 3 3 3 3 3 3 3]
[4 4 4 4 4 4 4 4 4 4]
[5 5 5 5 5 5 5 5 5 5]
[6 6 6 6 6 6 6 6 6 6]
[7 7 7 7 7 7 7 7 7 7]
[8 8 8 8 8 8 8 8 8 8]
[9 9 9 9 9 9 9 9 9 9]]
[0 1 2 3 4 5 6 7 8 9]
さて,まずはこのデータセットをテンソル化する前処理を「transforms」で記述しましょう。
transform = transforms.Compose([transforms.ToTensor()])
実際にテンソル化されるか確認してみましょう。
print(transform(data))tensor([[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2],
[3, 3, 3, 3, 3, 3, 3, 3, 3, 3],
[4, 4, 4, 4, 4, 4, 4, 4, 4, 4],
[5, 5, 5, 5, 5, 5, 5, 5, 5, 5],
[6, 6, 6, 6, 6, 6, 6, 6, 6, 6],
[7, 7, 7, 7, 7, 7, 7, 7, 7, 7],
[8, 8, 8, 8, 8, 8, 8, 8, 8, 8],
[9, 9, 9, 9, 9, 9, 9, 9, 9, 9]]])大丈夫そうですね。ここまではOKでしょうか。
それでは,次にラベルを与えて出力する「dataset」を定義していきましょう。上で観察したように,長さを取得できるように「len」を,インデックスを指定できるように「__getitem__」を定義していきます。ちなみに,「__getitem__」はPythonの特殊メソッドの1つで,「[]」で指定されたときの挙動を定めるものです。

となりますか…?大丈夫です。「クラスの継承」だけをおさえておけば,何もやっかいなことはありません。クラスの継承に関しては以下の記事でもお伝えしています。

Pytorchでは,偉い人が「dataset」の枠組みを作ってくれているのでした。その枠組みは,「torch.utils.data.Dataset」です。上の記事でもお伝えしていますが,基本的にこのような形でクラスは継承できます。
class 子クラス(親クラス): # 継承の文法
def __init__(self): # コンストラクタのオーバーライド
・・・
def hoge(self): #新しいメソッドの定義
・・・
この文法にしたがって,親クラス「torch.utils.data.Dataset」を継承して子クラス「MyDataset」を定義してみましょう。
class MyDataset(torch.utils.data.Dataset):
def __init__(self, data, label, transform=None):
self.transform = transform
self.data = data
self.data_num = len(data)
self.label = label
def __len__(self):
return self.data_num
def __getitem__(self, idx):
if self.transform:
out_data = self.transform(self.data)[0][idx]
out_label = self.label[idx]
else:
out_data = self.data[idx]
out_label = self.label[idx]
return out_data, out_label「__init__」で引数の処理をしておきます。「len」では引数の長さを返すように設定石ます。「__getitem__」では,上で確認した「transform」の出力を考えて,インデックスを指定したときにチャンネル0を指定するように設定します。なぜなら,チャンネル0にデータが保存されているからです。
実際に,確認してみましょう。
dataset = MyDataset(data, label, transform)
print(dataset[3])
print(len(dataset))(tensor([3, 3, 3, 3, 3, 3, 3, 3, 3, 3]), 3)
10しっかりと取り出せていることが分かります。さて,最後に「DataLoader」の定義をしていきましょう。今回は,既成の「DataLoader」を利用できるので,そうしてしまいましょう。
dataloader_shuffle = torch.utils.data.DataLoader(dataset, batch_size=2, shuffle=True)
dataloader_nonshuffle = torch.utils.data.DataLoader(dataset, batch_size=2, shuffle=False)
実際に出力して,バッチサイズに分割されたデータとラベルがテンソル化されて出力されるか確認してみましょう。「dataloader」はイテレータでしたので,for文を利用して出力を確認します。
for i in dataloader_shuffle:
print(i)out:
[tensor([[3, 3, 3, 3, 3, 3, 3, 3, 3, 3],
[5, 5, 5, 5, 5, 5, 5, 5, 5, 5]]), tensor([3, 5])]
[tensor([[7, 7, 7, 7, 7, 7, 7, 7, 7, 7],
[4, 4, 4, 4, 4, 4, 4, 4, 4, 4]]), tensor([7, 4])]
[tensor([[8, 8, 8, 8, 8, 8, 8, 8, 8, 8],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]), tensor([8, 1])]
[tensor([[9, 9, 9, 9, 9, 9, 9, 9, 9, 9],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), tensor([9, 0])]
[tensor([[6, 6, 6, 6, 6, 6, 6, 6, 6, 6],
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2]]), tensor([6, 2])]for i in dataloader_nonshuffle:
print(i)[tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]), tensor([0, 1])]
[tensor([[2, 2, 2, 2, 2, 2, 2, 2, 2, 2],
[3, 3, 3, 3, 3, 3, 3, 3, 3, 3]]), tensor([2, 3])]
[tensor([[4, 4, 4, 4, 4, 4, 4, 4, 4, 4],
[5, 5, 5, 5, 5, 5, 5, 5, 5, 5]]), tensor([4, 5])]
[tensor([[6, 6, 6, 6, 6, 6, 6, 6, 6, 6],
[7, 7, 7, 7, 7, 7, 7, 7, 7, 7]]), tensor([6, 7])]
[tensor([[8, 8, 8, 8, 8, 8, 8, 8, 8, 8],
[9, 9, 9, 9, 9, 9, 9, 9, 9, 9]]), tensor([8, 9])]
見事データセットとラベルが組み合わされて,バッチごとに出力されました!
応用編
最後に,自作データセットの応用編を見てみましょう。例えば,特徴量としてメル周波数対数スペクトログラムを利用するとします。(メル周波数対数スぺクトログラムに関してはコチラの記事を参照してください。)
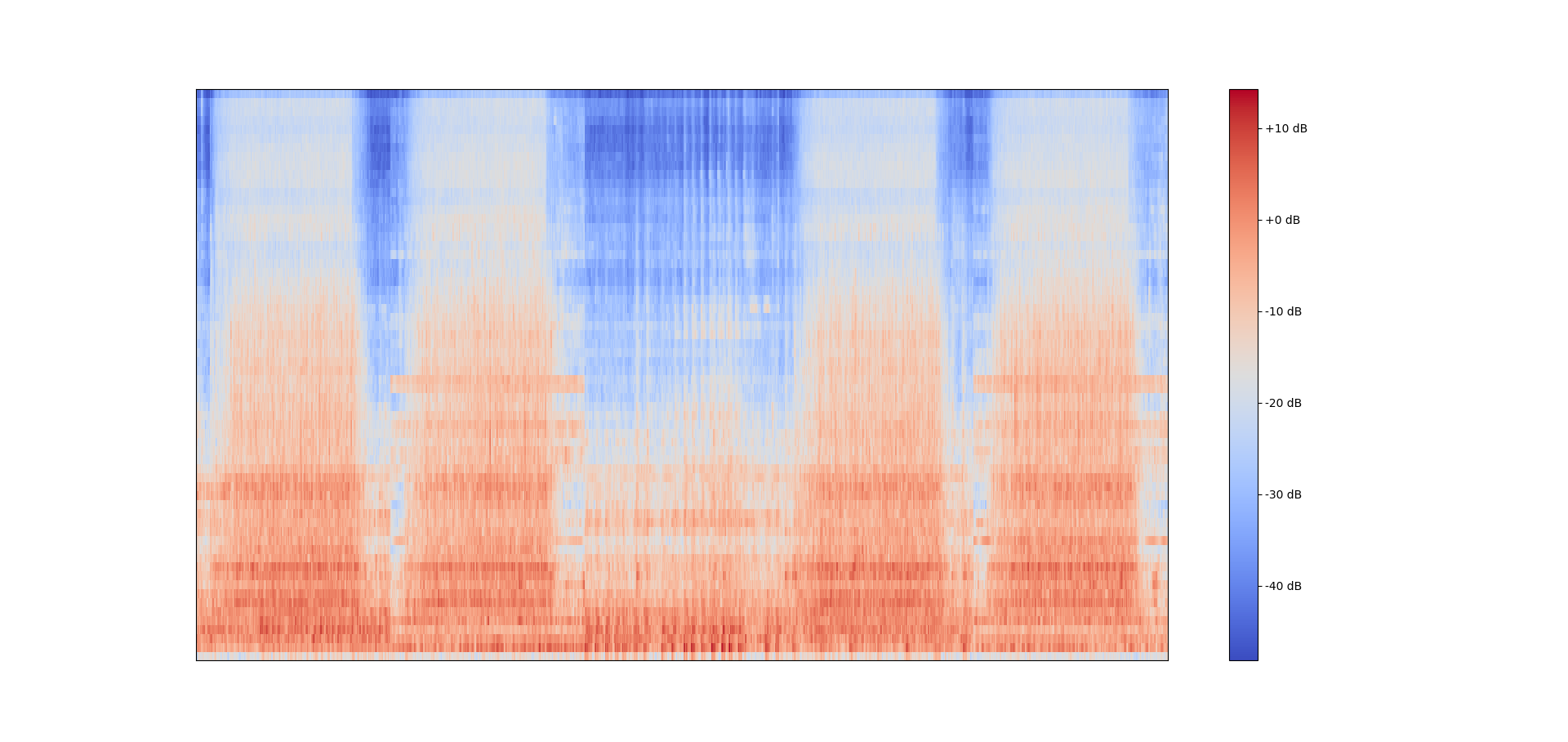 5つのwavファイルを並べたメル周波数スぺクトログラム
5つのwavファイルを並べたメル周波数スぺクトログラムpytorchのデータローダは与えられた入力から1つのインデックスを指定してバッチサイズに固めて返してくれるのでした。そこで,1つのインデックスが指定されたときに前後10フレームの特徴量を一緒に取ってくるようなデータセットも定義することができます。
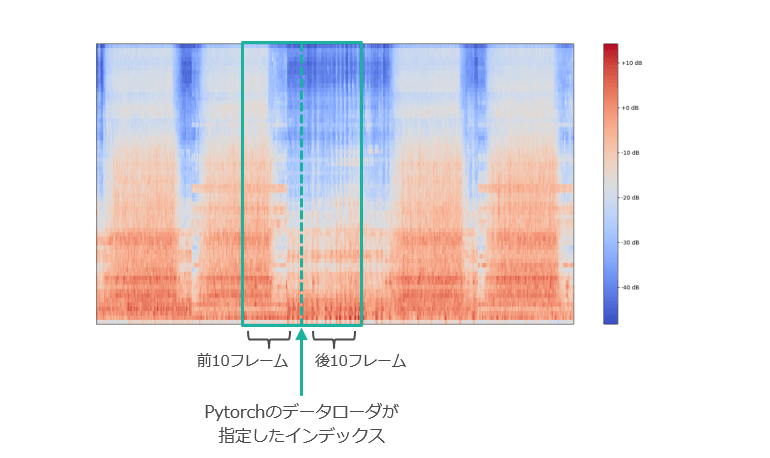
# ExpandDatasetは1つの時間フレームに対して前後10フレームを取得するようなデータセット
class ExpandDataset(Dataset):
def __init__(self, data, transform):
self.transform = transform
self.data = data
self.data_num = len(data)
# 最初の10インデックスと最後の10インデックスが選ばれた場合は前後10フレームを取得できないため反転パディングを施す
# 入力の次元数によって処理する軸が異なるため条件分岐
if self.data.ndim==2:
self.pad_data_fr = data[:10][::-1]
self.pad_data_bc = data[-10:][::-1]
self.pad_data = np.concatenate([self.pad_data_fr, data, self.pad_data_bc], axis=0)
elif self.data.ndim==3:
self.pad_data_fr = data[:,:10,:][:,::-1,:]
self.pad_data_bc = data[:,-10:,:][:,::-1,:]
self.pad_data = np.concatenate([self.pad_data_fr, data, self.pad_data_bc], axis=1)
def __len__(self):
return self.data_num
def __getitem__(self, idx):
if self.transform:
if self.data.ndim==2:
out_data = self.transform(self.pad_data)[0][idx:idx+20].flatten()
elif self.data.ndim==3:
index = int(random.uniform(0,self.data.shape[1]))
out_data = self.transform(self.pad_data)[:,idx, index:index+20].flatten()
else:
print("transformを使用しテンソル化してください")
return out_data
まとめ
機械学習は「データセットの収集と前処理が全て」なんて聞いたことがありますが,少しその理由を垣間見た気がします。ネットワークの定義などは,既成ライブラリを利用して比較的単純な作業で完了させることができます。
しかし,データセットの準備と前処理は,少し大変な作業になりそうです。考えてみればそれは当然で,ネットワークは誰もが使える「ツール」であるのに対し,データセットは目的や用途によって個人個人で異なるからです。
自分の研究に即したデータセットを利用するのが普通ですので,誰もが利用できるネットワークというツールを駆使するためにも,フォーマットを揃えたデータセットを準備することは必要不可欠な作業だと思います。












