
【超初心者向け】wavファイルからpythonで音響特徴量(メル周波数スペクトログラム・MFCC)を抽出してみる。



今回は,基本的な音響特徴量であるメルスペクトログラムとMFCCをPythonで抽出する方法をお伝えしていこうと思います。本記事はpython実践講座シリーズの内容になります。その他の記事は,こちらの「Python入門講座/実践講座まとめ」をご覧ください。

メル周波数スペクトログラムの概要
メル周波数スぺクトログラムとは,簡単にまとめると以下のような特徴量です。
●wavファイル(生の音)にSTFT(短時間フーリエ変換)を施して
●メルフィルタバンクを適用した特徴量
短時間フーリエ変換では,音の周波数に関する時間変化を表すスペクトログラムという特徴量を得ることができます。そのスペクトログラムを,人間の聴覚特性にフィットするような形に整形(=メルフィルタバンクを適用する)したものがメル周波数スぺクトログラムです。
ちなみに,MFCC(メル周波数ケプストラム係数)は,メル周波数スペクトログラムをさらに離散コサイン変換してケプストラム領域に飛ばし,そのうち低次元の係数をとってきた特徴量のことを指しています。一昔前までは,音響特徴量といえばMFCCでしたが,深層学習が利用されるようになってからはメル周波数スペクトログラムもよく利用されています。
機械学習で利用するために
機械学習で利用することを考えれば,複数のwavファイルから音響特徴量を「並べる」必要があります。ここは色々な流派がありますが,1つのファイルにまとめてしまった方が特徴量としては扱いやすくなります。
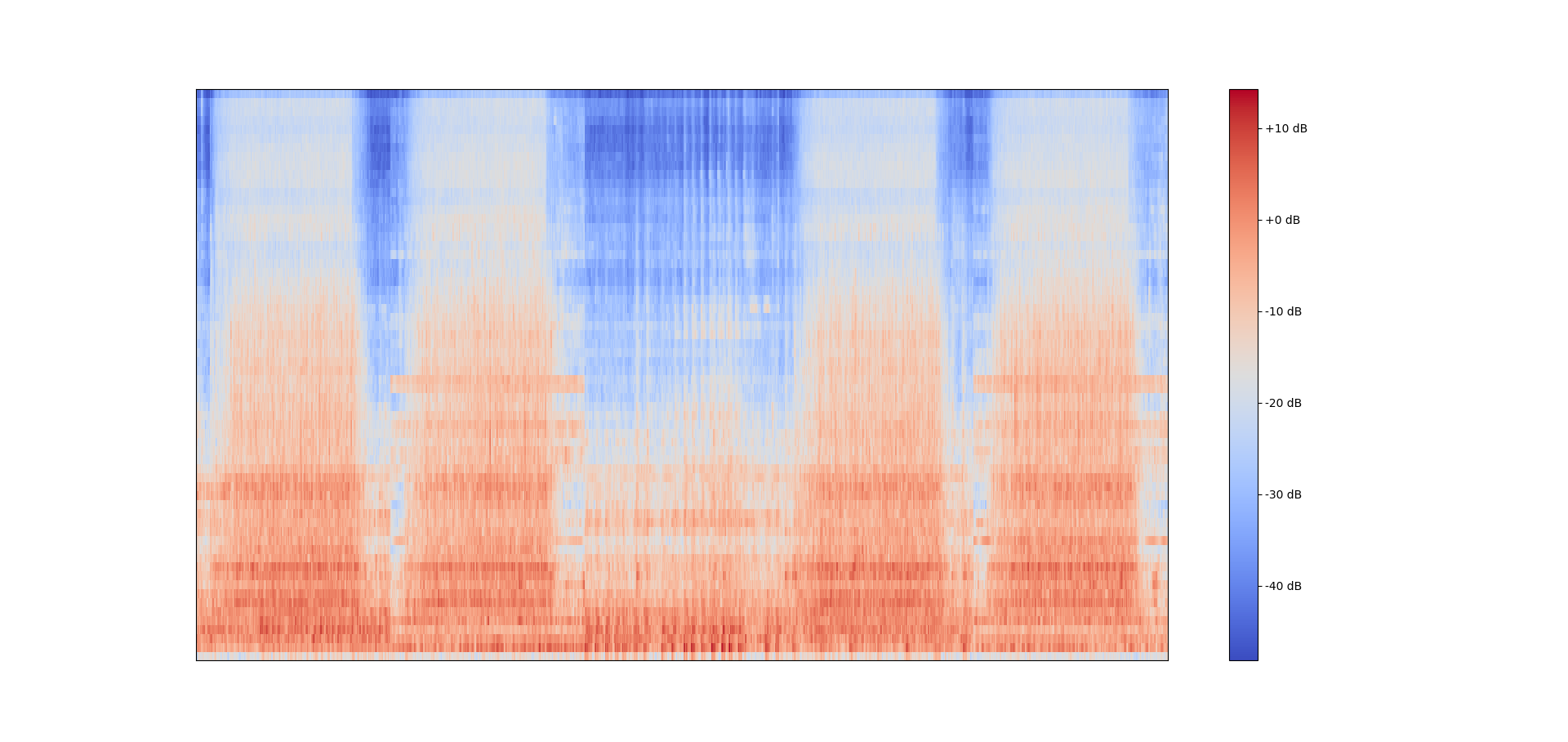 5つのwavファイルを並べたメル周波数スぺクトログラム
5つのwavファイルを並べたメル周波数スぺクトログラムそこで,以下の実装では「複数のwavファイルから得られたメル周波数スぺクトログラムを並べて1つの大きなスペクトログラムを作る」ことを目標としていきたいと思います。
実装
さっそく実装を確認していきましょう。
必要なライブラリ等のインポート
import librosa
import glob
import numpy as np音を扱う際に,非常に便利なライブラリとしてlibrosaがよく利用されます。また,globは読み込むwavファイルの名前(パス)を取得するために利用します。出力はnumpy形式に揃えます。
メル周波数スぺクトログラムを抽出する関数
def extract_mel(wav, sr, n_mels=64): #Output -> (timeframe, mel_dim)
audio, _ = librosa.load(wav, sr=sr)
mel = librosa.feature.melspectrogram(y=audio, sr=sr, n_mels=n_mels).T
return melwavファイルを読み取ってメルスペクトログラムに変換しています。
スペクトログラムを並べる関数
def data_list(path, sr, n_mels=64):
wav_list = glob.glob(path)
size = len(wav_list)
data = np.ones((1, n_mels))
count= 0
for wavname in wav_list:
component = extract_mel(wavname, sr=sr, n_mels=64)
data = np.concatenate([data, component], axis=0)
count += 1
sys.stdout.write("\r%s" % "現在"+str(np.around((count/len(wav_list))*100 , 2))+"%完了")
sys.stdout.flush()
return data[1:], size得られたスぺクトログラムを並べる関数です。wavファイルが大量にある場合は少し時間がかかるため,現在何%進行中かを出力するコードも入れています。この関数を適用すれば,所望の特徴量を得ることができます。
まとめ
音響特徴量は画像とは似て非なるものです。画像分野で利用された手法を「スペクトログラムを画像と見立てて」適用する研究は非常に盛んですが,我々は音響を扱う研究者である以上,画像に最適化された手法を音響に最適な形に変換して適用しなくてはなりません。その第一歩として,音響特徴量のエンジニアリングが大切になってきます。今回はライブラリに頼りましたが,そのうち自作ライブラリで音響特徴量を抽出するような記事を書きたいと思います。














