
【超初心者向け解説】異常検知用データセット「ToyADMOS」の詳細。



今回は,異常音検知タスクのデータセットであるToyADMOSの使い方をお伝えしていこうと思います。本記事はpython実践講座シリーズの内容になります。その他の記事は,こちらの「Python入門講座/実践講座まとめ」をご覧ください。

ToyADMOSの概要
ToyADMOS[1]は,2019年にNTT研究所で作成された異常音検知用のデータセットです。論文[1]とこちらのGitHubリポジトリより詳細を確認することが可能です。
簡単に内容をまとめてしまうと,ToyADMOSには3種類の状況が設定されており,それぞれではおもちゃを使って正常音と異常音を収録しています。つまり,ToyADMOSで想定されているタスクはanomaly detection(異常音検知)の中でも「正常 or 異常」の二値ラベリングの問題と捉えることができます。
コチラの記事でもお伝えしていますが,音響イベントや音響シーンに関する問題設定としては,以下のような代表例が挙げられます。
【主な問題設定とその解法】
●音響シーン分類
→音響シーンを分類する問題
●音響イベント分類
→単一の短時間音響イベントにラベルを付与
●音響イベント検出
→複数の長時間音響イベントにラベルを付与
●異常音検知
→正常音以外の音が含まれる区間の検知
異常音検知は,問題設定の中の一つの分類だということが分かります。しかし,ToyADMOSデータセットは,正常音以外の音が含まれる区間の「検知」には利用しません。なぜなら,異常音が含まれる区間の正解ラベルが与えられていないからです。
ToyADMOSは,音を「正常 or 異常」で二値分類するタスクを想定していると考えられます。そこで,ToyADMOSのデータセットとしての位置づけを確認するために,今年のICASSPで発表された「Detection and Classification of Acoustic Scenes and Events」を引用していきたいと思います。ICASSPのチュートリアルに関しては,当サイトの記事もぜひ参考にしてください。
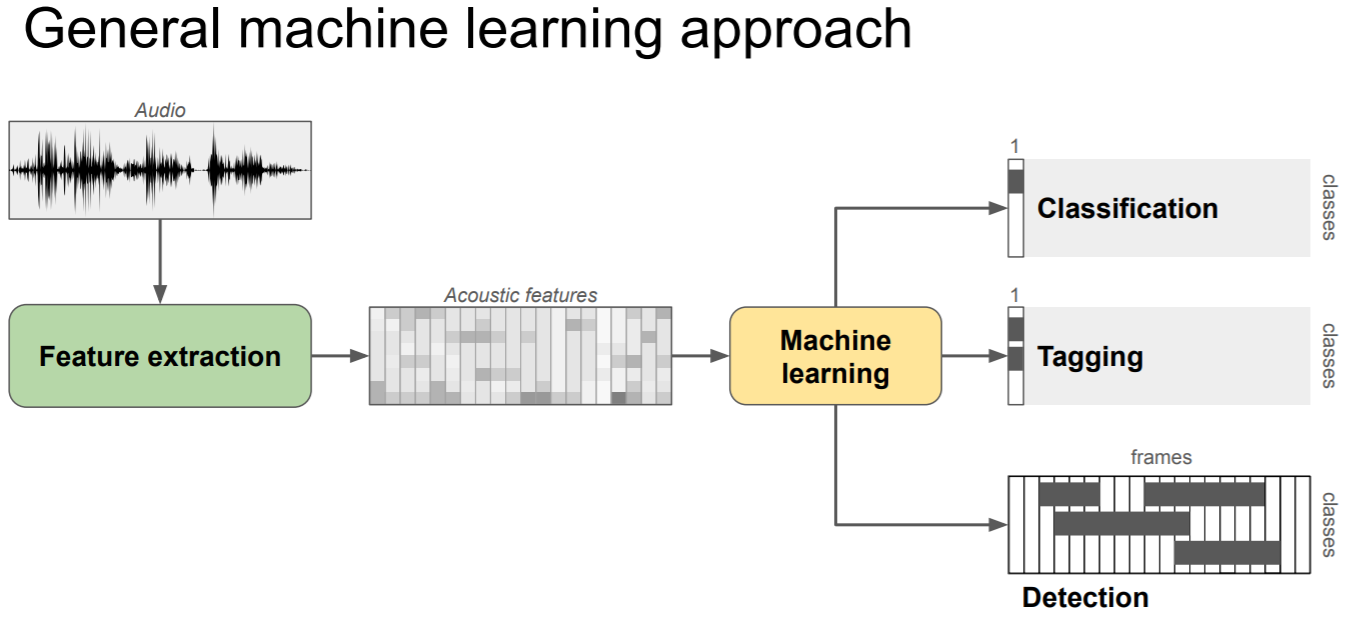 機械学習の一般的なアプローチ概観
機械学習の一般的なアプローチ概観音から抽出された特徴量を利用して,「分類(classfication)」もしくは「タグ付け(tagging)」するというタスクがToyADMOSの想定する問題です。一番下の「検出(detection)」はDCASEなどのデータセットの範疇になります。
詳細
ToyADMOSの3種類の状況とは,「ToyCar」「ToyConveyor」「ToyTrain」になります。ToyCarは製品の欠陥品をチェックするためのタスク,ToyConveyorは固定された機器の異常をチェックするためのタスク,ToyTrainは移動機器の異常をチェックするためのタスクになっています。
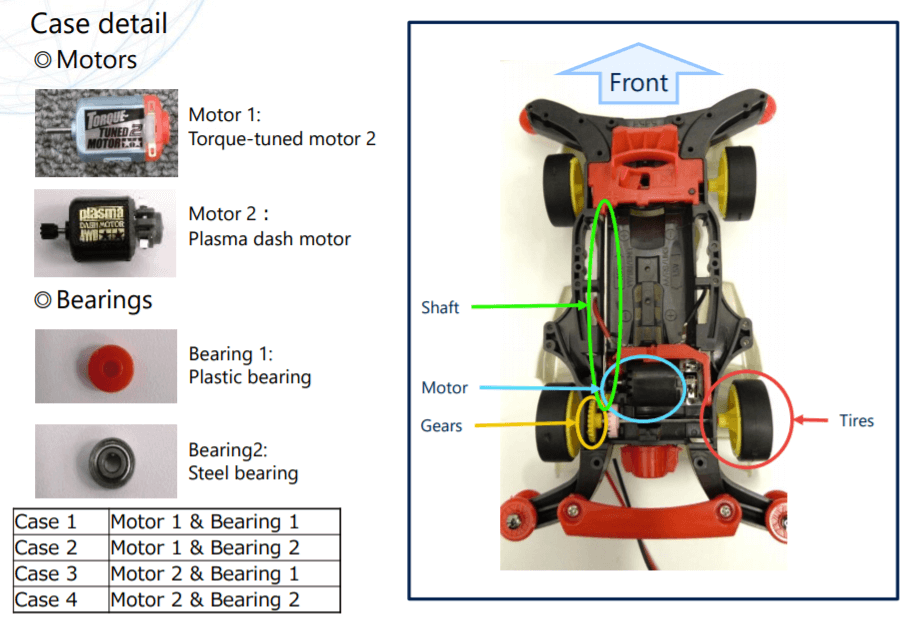 ToyCarの詳細(出典[1])
ToyCarの詳細(出典[1]) ToyConveyorの詳細(出典[1])
ToyConveyorの詳細(出典[1]) ToyTrainの詳細(出典[1])
ToyTrainの詳細(出典[1])それぞれの音は様々なノイズレベルの下で収録されているため,使用される分類器には汎化性能が求められます。また,4つのマイクロフォンで音を拾っているため,最大4チャネルを使用することが可能です。また,個々の機器データにも微妙な差異を作っているため,テスト時にはモデルの適応能力が試されます。データセットの詳細は,以下の通りです。
【音の種類】
●Normal sound:正常音
●Anomalous sound:異常音
●Environmental sound:背景雑音
【音ファイルの形式】
●IND:スタートとストップがある(先頭と末尾に無音区間アリ)
●CNT:連続したファイルの一部(先頭と末尾に無音区間ナシ)
INDとCNTは,音の種類によってまちまちです。READMEで示されている表でまとめておきます。
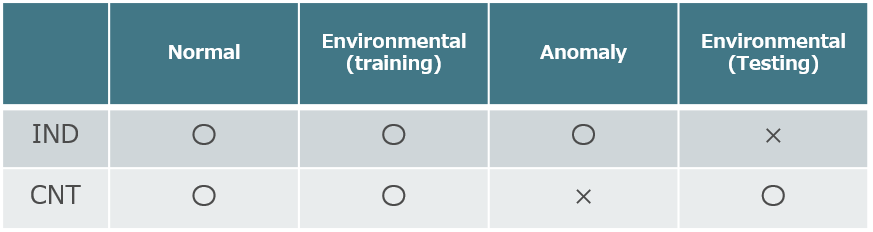 各音の種類におけるINDとCNTの有無
各音の種類におけるINDとCNTの有無論文で指定されているToyADMOSの限界は,収録対象がおもちゃであるという点です。実際の環境下で同様のモデルを利用する場合は,ハイパーパラメータ等を調整する必要があるとの記述があります。
簡単な使用方法
こちらのGitHubリポジトリのREADMEに,簡単な使用方法が説明されています。今回は,その方法に従って簡単なデータを作っていきたいと思います。
データセットのダウンロード
こちらのURLからデータセットをダウンロードすることができます。非常に大きなファイルですので,zip圧縮ファイルがいくつかに分割されて配布されています。すべてのファイルが揃わなければzipファイルを解凍することができないので,ご注意ください。
かなり容量が大きいので,時間がかかると思います。ブラウザによっては一回にダウンロードできるファイル数に制限がある場合があるので,気を付けてください。
ファイルのダウンロード
こちらのGitHubリポジトリ上のファイル「C01_create_small_INT_dataset」「E01_simple_AE_test」「anomaly_conditions」をダウンロードしてください。また,「C01_create_small_INT_dataset」「E01_simple_AE_test」で指定されているデータセットへのパスを,ご自身のダウンロードしたディレクトリへのパスに変更してください。
 「make_dataset_for_car_and_conveyor.py」の中身。データセットへのpathを変更してください。ToyCarとToyConveyorはそれぞれここで指定する必要があります。
「make_dataset_for_car_and_conveyor.py」の中身。データセットへのpathを変更してください。ToyCarとToyConveyorはそれぞれここで指定する必要があります。 「make_dataset_for_train.py」の中身。データセットへのpathを変更してください
「make_dataset_for_train.py」の中身。データセットへのpathを変更してくださいここで一点注意なのですが,「make_dataset_for_train.py」のコメントで「ToyCar」か「ToyConveyor」を選びなさいと書いてありますが,「for_train」と書いてあるくらいなのでtrain以外は選べませんのでご注意ください。(おそらく「for_car_and_conveyor」からのコピペをそのまま使われているものと思われます)
もう一点注意するべきなのは,01_train.pyと02_test.pyでGPUの指定(DEVICE_NUM )が異なるという点です。どちらも0に統一しておけばエラーは起こらないと思います。
データセットの作成
$ python make_dataset_for_car_and_conveyor.py # subdataset="ToyCar"
$ python make_dataset_for_car_and_conveyor.py # subdataset="ToyConveyor"
$ python make_dataset_for_train.py # subdataset="ToyTrain"ターミナル上で,上のコマンドをたたいてみましょう。パラメータ設定がうまくいっていれば,エラーが起こらず「正常音+背景雑音(学習用)」「正常音+背景雑音(テスト用)」「異常音+背景雑音(テスト用)」のデータセットが作成が作成されるはずです。エラーが発生してしまう場合は,パラメータやデータセットへのパスの設定を見直しましょう。
モデルの学習
$ python ./E01_simple_AE_test/01_train.py
# toy_typeは02_test.pyとそろえる
# ToyADMOS-dataset-masterディレクトリにいる場合今回は単純なオートエンコーダで正常音を学習していきます。
テストの実行
$ python ./E01_simple_AE_test/02_test.py
# toy_typeは01_train.pyとそろえる
# ToyADMOS-dataset-masterディレクトリにいる場合このコマンドを実行すれば,ROC曲線とAUCの値,FPRを0.1に抑えた時のF値が出力されると思います。
まとめ
2019年に発表された異常音検知のためのデータセットでした。異常音検知は,DCASEなどのコンペデータセットなどが有名であるものの,基本的にデータセットは充実していない分野です。ましてや,異常音の二値分類のためのデータセットはいまだにありませんでした。今回異常音二値分類のデータセットが発表されたことで,異常音検知分野の人気がますます高まると思います。
[1] Koizumi, Yuma, et al. “ToyADMOS: A Dataset of Miniature-Machine Operating Sounds for Anomalous Sound Detection.” arXiv preprint arXiv:1908.03299 (2019).











