
【サーベイまとめ】解説誌要約「音響イベントと音響シーンの分析」

この記事では,研究のサーベイをまとめていきたいと思います。ただし,全ての論文が網羅されている訳ではありません。また,分かりやすいように多少意訳した部分もあります。ですので,参考程度におさめていただければ幸いです。
間違えている箇所がございましたらご指摘ください。随時更新予定です。他のサーベイまとめ記事はコチラのページをご覧ください。
本記事の内容
本記事では,「音響イベントと音響シーンの分析」[井本, 2018][1]を要約したものを簡単にまとめていきます。
はじめに
近年,計算機環境や機械学習理論の発展により,あらゆる音の分析が可能になっています。従来は,音の対象を音声や音楽に限定していましたが,今では音の種類の推定(音響イベント検知)や周囲の環境の推定(音響シーン分析)が盛んに研究されるようになっています。
【本解説に含む内容】
●音響イベントや音響シーン分析の問題設定
●用語の使い方
●利用可能なデータベース
●音響イベントや音響シーン分析特有の課題
●最新の研究動向
用語の定義
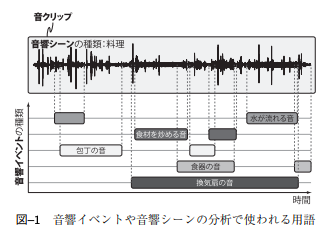 出典:[1]
出典:[1]【よく使われる単語】
●音クリップ(Soundclip, audio clip)
→分析の単位となる音のかたまり
●音響シーン(Acoustic scene)
→音が収録された状況や周囲にいる人の行動
●音響イベント(Acoustic event)
→より細かい音の種類
問題設定
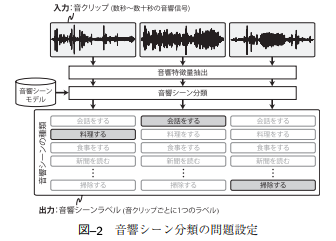 出典:[1]
出典:[1]【主な問題設定とその解法】
●音響シーン分類
→音響シーンを分類する問題
・基本的に機械学習を利用
・音響特徴量はMFCCやMPEG-7 音響特徴量
・モデルはGMM,HMM,SVMなど
・最近ではスペクトログラムを画像と見立てたCNNも
●音響イベント分類
→単一の短時間音響イベントにラベルを付与
※実際の環境下では音響イベントが重複することから現実的な問題ではない
●音響イベント検出
→複数の長時間音響イベントにラベルを付与
・「区間」と「種類」の推定
・NMFの利用
・DNNの利用
●異常音検知
→正常音以外の音が含まれる区間の検知
・どれだけ正常音モデルから逸脱しているかが基準
・学習データ集めが困難
・少し異常音データが手に入る場合…
→正常音からモデル化した「音に共通するルール」を異常音も学習
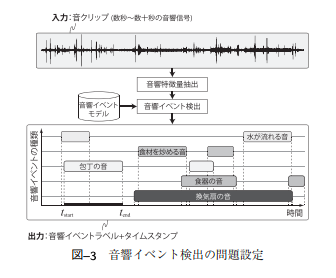 出典:[1]
出典:[1] 出典:[1]
出典:[1]
データセット
【よく利用されるデータセット】
●RWCP 実環境音声・音響データベース(RWCP-SSD)
・音響イベント分析の入門的な立ち位置
・105種類の音響イベントが合計1万サンプル程度
●TUT Acoustic Scenes 2017
・15の音響シーンを含む開発用データ+評価用データ
・クリップの長さは10秒に統一
・分割方法は4分割の交差検証に指定
●TUT Sound events 2017
・TUT Acoustic Scenes 2017に含まれる音響イベントを抽出
・各音クリップには重複した音響イベントが含まれている
・各カテゴリ間にサンプル数の差がある
●TUT Rare Sound Event 2017
・3種類の音響イベント
・背景音
・混合音を作るためのPythonのスクリプト
●AudioSet
・632種類の音響イベントが合計200万サンプル程度
・クリップはYoutubeの一部で長さは10秒
・ラベルは音オントロジーに基づく階層構造
・WordNetやImageNetに相当する音のデータセット
●CHiME-Home
・1つのクリップには単一の音響イベント
・長さは4秒
・ラベルは音声とそれ以外というような分け方
●UrbanSound,UrbanSound8K
・屋外で発生する音響イベント
●ESC(Environmental sound classification)
・Freesoundから抽出された音響イベント
●DIRHA Simulated Corpus
・多チャンネルマイクロホンによる音響イベント
●Multi-channel Acoustic Event Dataset
・多チャンネルマイクロホンによる音響イベント
立ちはだかる課題
音響イベント検知や音響シーン分析で困難となる問題として,コーパス作りが挙げられます。一般にも,コーパス作りには労力が必要であることが知られていますが,特に音響イベントや音響シーンに関してはラベルの種類の多さがコーパス作りを困難にしています。また,音響イベントは重複することが多いため,発生時刻と終了時刻のラベル付与に時間を要してしまう場合があります。
他にも,雑音や欠損データの影響を受けやすいという特徴が挙げられます。音データのやりとりに通信を行なっている場合は,パケットロスなどによる音の欠損を含むデータを対象とすることになります。
データの量と質による技術の分類
 出典:[1]
出典:[1]上で指摘した課題から,音響イベント検知と音響シーン分析では「データ量」と「データの質」という軸で技術を俯瞰することが考えられます。データの質に関しては,雑音を分離する技術を流用することが考えられますが,音声認識等とは雑音の定義が異なる場合が多いため,簡単には流用できないのが現実です。
他にも,プライバシーの観点から,欠損したデータを扱えるようにすることも非常に重要です。例えば,欠損した音を潜在変数として扱うモデルが考案されています。また,質の低い音のデータセットも作る必要があると指摘されています。
空間情報の活用
音響イベントや音響シーンでは,空間情報の持つ意味合いが大きいです。例えば,実際に怒っているイベントと,テレビの中から聞こえたイベントでは,イベントのもつ意味が大きく異なってきます。一方で,現状ではIoT機器とマイクロフォンアレイを組み合わせた場合に「録音開始時間の同期」や「サンプリング周波数のミスマッチ」という問題が起こります。空間情報を活用するためには,これらの問題を克服するような手法が提案される必要があります。
小規模データを対象とする場合
学習データを収集することの難しさから,小規模データを対象とする手法の研究も進んでいます。スパース性を兼ね備えた数学的なモデルとしてNMFが挙げられますが,実際の精度は十分なものとはいえません。現在では,深層学習を利用した手法がよく用いられています。
大規模データを対象とする場合
コーパス作成を半自動化することで,必要なコストを削減しようとする動きも見られます。例えば,弱ラベルを利用した音響イベント検知や,既存のデータセットを拡張する手法に注目が集まっています。
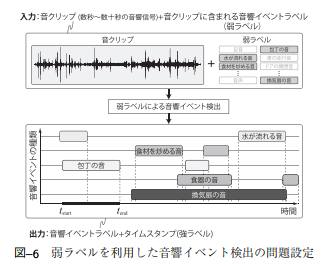 出典:[1]
出典:[1]開始時刻と終了時刻を付与された音響イベントラベルを強ラベル,時刻が付与されない音響イベントラベルを弱ラベルと呼びます。問題設定としては,音響イベントラベルを入力して弱ラベルを作成し,強ラベルを推定するというものです。既存データの拡張に関しては,CNNやGANがよく用いられます。
まとめ
音響イベント検知,音響シーン分析は非常に難解な問題であることが感じられました。ここでも,やはり深層学習に基づくモデルの利用が盛んですね。そうなると,問題はやはり学習データセットの作成ということになるでしょう。本文中にもあったように,既存データの拡張をすることで学習データの不足分を補うことが期待されます。これ以降,深層生成モデル等を利用して学習データを作成する試みがあってもおかしくないと思います。
[1] 井本桂右. “音響イベントと音響シーンの分析.” 日本音響学会誌74.4 (2018): 198-207.












