
【サーベイまとめ】チュートリアル要約「Detection and Classification of Acoustic Scenes and Events(ICASSP 2019)」

この記事では,研究のサーベイをまとめていきたいと思います。ただし,全ての論文が網羅されている訳ではありません。また,分かりやすいように多少意訳した部分もあります。ですので,参考程度におさめていただければ幸いです。
間違えている箇所がございましたらご指摘ください。随時更新予定です。他のサーベイまとめ記事はコチラのページをご覧ください。
読みたい場所へジャンプ!
本記事の内容
本記事では,「Detection and Classification of Acoustic Scenes and Events」[ICASSP, 2019][1]を要約したものを簡単にまとめていきます。
アウトライン
【セッション1:機会学習アプローチ】
●問題設定
●一般的な機械学習アプローチ
●Pythonによる音分類
●タスク特有の処理データセットや評価について
【セッション2:応用手法】
●Pythonによる音響イベント検知
●実生活における問題と解法
●将来に向けて
イントロ
日常に潜む情報は,公共のシーン(お誕生日会,道,家…)と個々のシーン(車,クラクション,犬の鳴き声…)に分けられます。前者の解析には音響シーン分析が用いられ,後者の解析には音響イベント検知が用いられます。
音響シーン分析とは,音響的なシーンをある特定のラベルと結びつける操作を指します。利用されるラベル例としては,以下のようなものが挙げられます。
Airport/Indoor/shopping mall/Metro station/Pedestrian street/Public square/Street with medium level of traffic/In tram/In bus/In metro/Urban park/Cafe Restaurant/In car…
音響イベント検知とは,音の発音区間と種類のラベルを推定する操作のことを指します。複数の音響イベントが重複する可能性もあります。ラベルの種類としては,以下のような例が挙げられます。
Baby crying/Glass breaking/Gunshot/Train horn/Air horn/Car alarm/Reversing beeps/Ambulance siren/Police car siren/Civil defense siren/Screaming/Bicycle/Skateboard/Car passing by/Bus/Truck/Motorcycle
 出典:[1]
出典:[1]また,ラベルのみを指定しておく「弱ラベル」という概念にも軽く触れられています。対して,発音区間も付与するラベルを「強ラベル」と呼びます。
 出典:[1]
出典:[1]
また,音響シーン分析と音響イベント検知は,補聴器や自動運転技術などにも利用されています。他にも,赤ちゃんのモニタリングや鳥の鳴き声検出,自動字幕付与などにも応用されています。
似たような分野としては,音声認識や音楽情報検索等が挙げられます。これらの分野との共通点としては,使用される音響特徴量やベースとなる機械学習の手法が挙げられます。一方,相違点としては音響シーン分析とイベント検知は分類体系が明確でない点や,独立な因子が多く含まれている点,データセットがまだまだ少ないという点が挙げられます。
一般的な機械学習の手法
音響イベント検知や音響シーン分析は,一般に非常に難しいタスクなので,基本的に教師あり学習を行います。また,分類されるクラス数も事前に分かっているものとし,音響信号とラベルを対応させるマッピングを学習させます。
音響特徴量としてはMFCCが使われることが多く,ベースとなる手法は以下のように発展してきました。
【機械学習の発展】
●CNN(普遍的な特徴量の取得)
●RNN(時系列前後の情報活用)
●End-to-end(複数のネットワークの組み合わせ)
各タスクのモデル概略
 一般的なアーキテクチャ
一般的なアーキテクチャ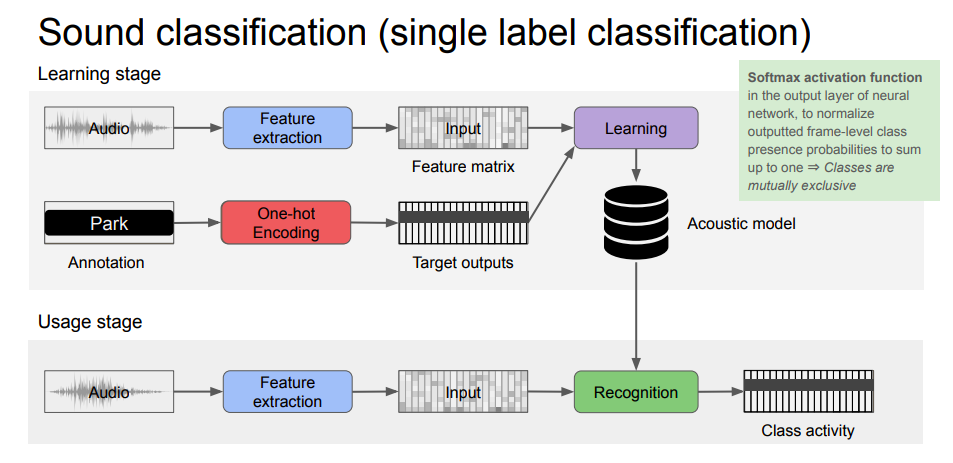 単一ラベル分類
単一ラベル分類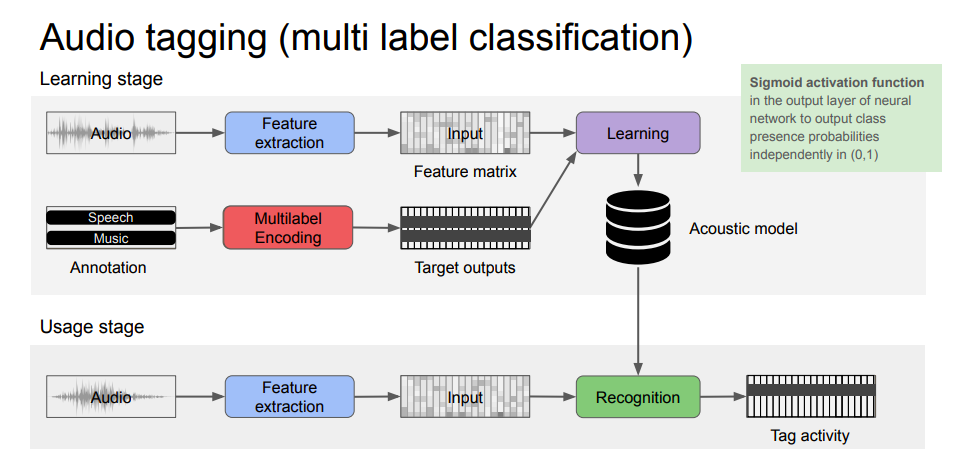 マルチラベル分類
マルチラベル分類 音響イベント検知
音響イベント検知イメージとしては,まず基本となるアーキテクチャとして「単一ラベル分類」が挙げられます。それを複数のラベルに適用したアーキテクチャとして「マルチラベル分類」が挙げられます。最終形態として,複数ラベルのオーバーラップを許した音に対してラベルと発音区間を付与する音響イベント検知が挙げられます。
データセット
【データセット(音)に求められる要素】
●多様性(カテゴリー・状況)
●サンプル数
【データセット(ラベル)に求められる要素】
●明確さ
●一対一対応
特に,ラベルに関して補足を加えておきます。ラベルを人手で記述するのは非常に手間がかかります。そこで,発音区間をあらかじめ区切っておいて,使用されるラベルも制限しておくようなラベル付与の手法がとられることもあります。
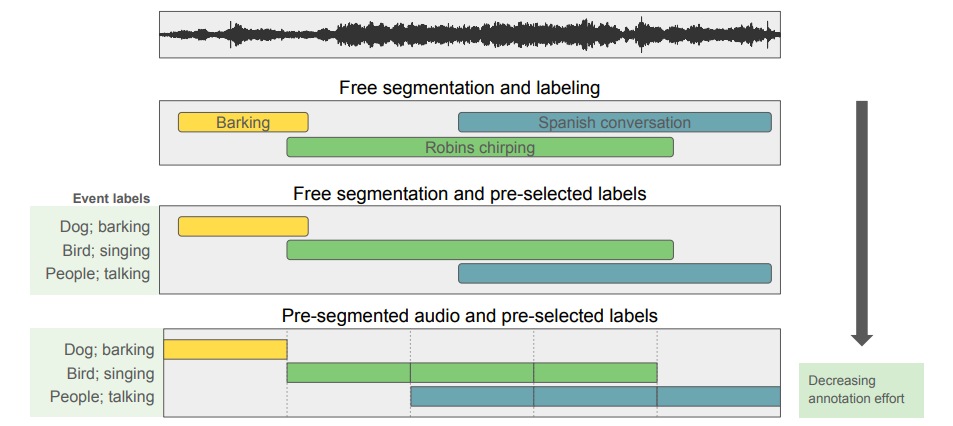 出典:[1]
出典:[1]この図では,下に行けば行くほどラベル付与の手間が省けます。
データセットの例としては,以下のようなものが挙げられます。
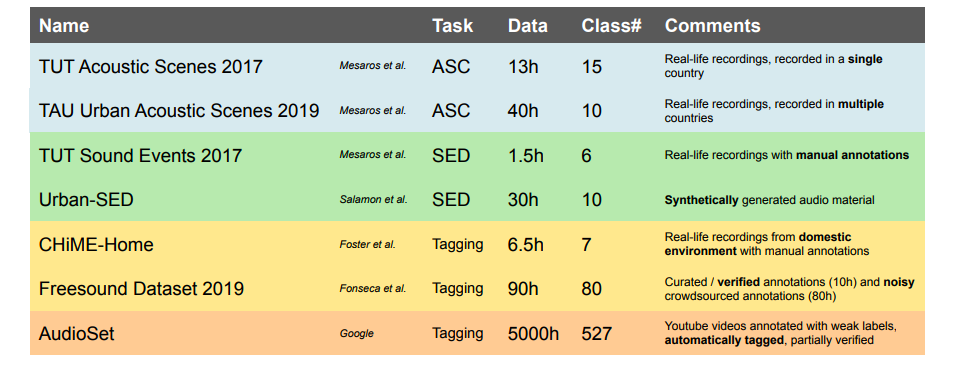 出典:[1]
出典:[1]より詳しい情報は,こちら(http://www.cs.tut.fi/~heittolt/datasets)にまとまっています。
評価
一般的な方法で,モデルの出力の0,1とラベルの0,1の4通りの組み合わせによって行われる評価が挙げられます。
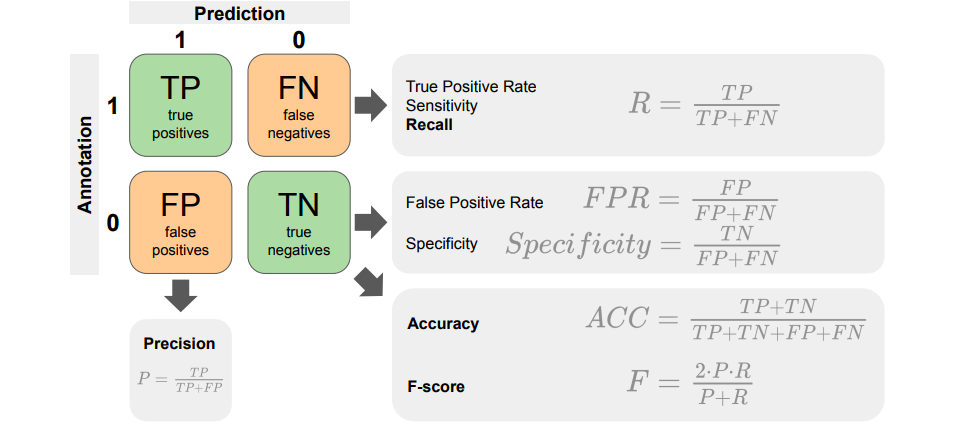 出典:[1]
出典:[1]評価方法には,主に二種類のアプローチが挙げられます。
【評価方法】
●Segment-based
→区間ごとにTP, FP, TN, FN等で評価
●Event-based
→イベントごとに200msなどのバッファをもたせて評価
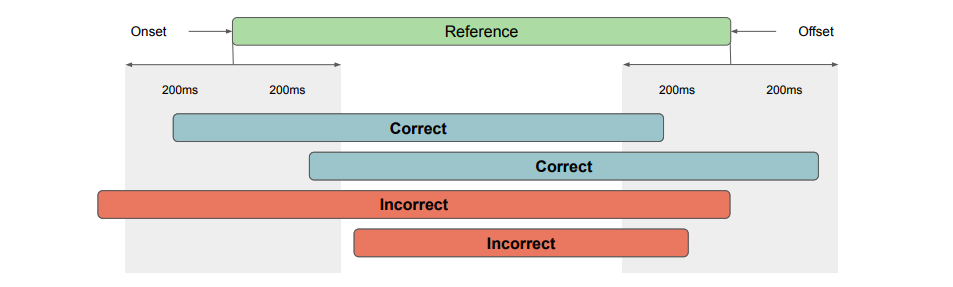 出典:[1]
出典:[1]よく利用される指標としては,以下のようなものがあります。
【よく利用される指標】
●Accuracy
\begin{eqnarray}
\text{Accuracy} &=& \frac{TP+TN}{TP+FP+TN+FN}
\end{eqnarray}
●F値
\begin{eqnarray}
\text{F-score} &=& \frac{2PR}{P+R}\\
\text{P} &=& \frac{TP}{TP+FP}\\
\text{R} &=& \frac{TP}{TP+FN}
\end{eqnarray}
●Error-Rate(Segment-based)
\begin{eqnarray}
\text{Error-Rate} &=& \frac{\sum S(k) + \sum D(k) + \sum I(k)}{\sum N(k)}\\
N(k) &=& \text{セグメントの総数}\\
S(k) &=& \text{FPとFNの共通部分}\\
D(k) &=& \text{Sで現れなかったFN}\\
I(k) &=& \text{Sで現れなかったFP}
\end{eqnarray}
これらの評価指標を比較してみます。
【利点】
●Accuracy
→シンプルさ
●F値
→よく知られてて分かりやすい
●Error-Rate
→音声認識との互換性がある
【欠点】
●Accuracy
→クラス間のバランスに影響を受けやすい
●F値
→平均的なスキームが重視される
●Error-Rate
→1.0を越す場合がある
課題の解決と応用手法
セッション2では,音響イベント検知と音響シーン分析に関する課題と,その解決方法の試みについて紹介されていました。1つずつ簡単に見ていきます。
ラベル付与にコストがかかりすぎる
弱ラベルを利用することで,ラベル付与にかかるコストを削減できます。アプローチ方法としては,個々のセグメントに対して推定を行うのではなく,ある程度のまとまりごとに行う手法が紹介されています。attention-basedの方法も利用できるとのことです。欠点としては,強ラベルに対する評価が求められる点が挙げられます。
学習データが足りない
既存のデータから学習データを増強する試みがあります。単純な方法としては,既存のエータをミックスして新しい学習データとする方法があります。欠点としては,実際の学習データほどの複雑性を再現できない点が挙げられます。
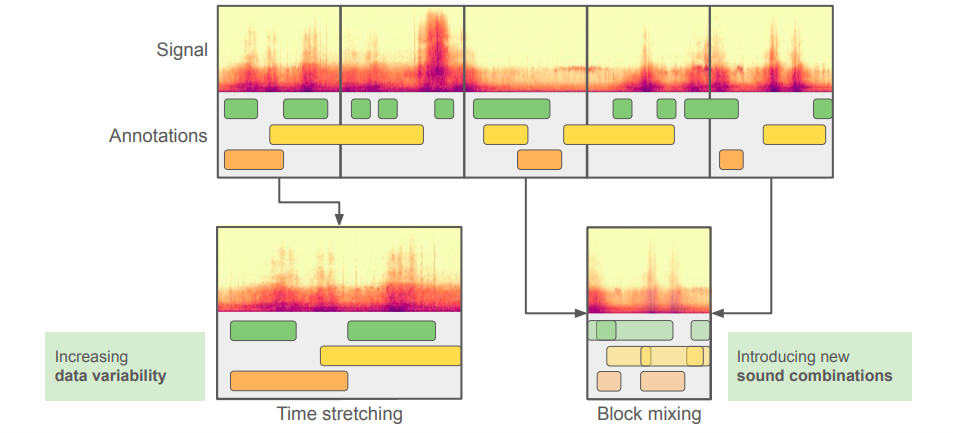 出典:[1]
出典:[1]
複雑なモデルに対する必要なデータ量の多さ
モデルが複雑になればなるほど,必要な学習データ量も増えてしまいます。そこで,学習済みモデルを転用する転移学習という手法が採用されることがあります。一方で,何が転移可能な知識なのかを選択する部分に課題が残っています。
まとめ
音響イベント検知,音響シーン分析の分野では,学習データ集めがかなりの問題となっていることが伝わってきました。半教師あり学習や転移学習,能動学習等を利用するという王道の回避手段が考案されている一方で,自動的にラベルを付与する研究も行われている点は興味深いです。モデル自体の性能と学習データの集め方が並行して発展させていくべき分野なのではないかと感じました。
[1] http://www.cs.tut.fi/~heittolt/pubs/ICASSP2019_DCASE_tutorial.pdf











