【超初心者向け】TensorFlowのチュートリアルを読み解く。<その2>



本シリーズでは,ディープラーニングを実装する際に強力な手助けをしてくれる「TensorFlow」についてです。公式チュートリアルを,初心者に向けてかみ砕きながら翻訳していこうと思います。(公式ページはこちらより)
今回はNo.2で,「分類」編です。その他の記事は,こちらの「TensorFlowの公式チュートリアルを初心者向けに読み解く」をご覧ください。
基本的な流れ
TensolFlowでディープラーニングを実装する流れは,以下のようになります。
●データセットの読み込み
●ネットワークの定義
●最適化アルゴリズムの定義
●学習の実行
●評価の実行
●予測の実行
必要なモジュール等の準備
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plttensorflowとkerasをインポートしましょう。計算用にnumpy,可視化用にmatplotlib.pyplotもインポートします。
データセットの読み込み
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']mnistの中でも画像の分類テスクであるfashion_mnistをデータセットとして利用します。のちにラベルクラスの名前が必要になるため,手作業でラベルの名前を付けていきます。
データセットの概要を確認しましょう。
print(train_images.shape)
print(test_images.shape)
print(len(train_labels))
print(len(test_labels))(60000, 28, 28)
(10000, 28, 28)
60000
10000画像データは28×28のサイズで,訓練用に60000枚,テスト用に10000枚用意されています。ラベルは画像データの枚数と同じです。
一応,可視化して確認します。
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.gca().grid(False)
plt.show()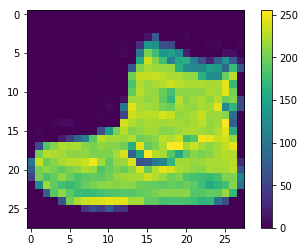
画像データの各要素は[0,255]の値を取るので,[0,1]に変換します。こうすることで,ネットワークの中のパラメータが取る値が扱いやすくなります。
train_images = train_images / 255.0
test_images = test_images / 255.0
一応,可視化して確認します。
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()
ネットワークの定義
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation=tf.nn.relu),
keras.layers.Dense(10, activation=tf.nn.softmax)])一行目で,kerasのsequentialモデルのインスタンスを生成しています。sequentialモデルは深層学習の中でも最も基本的なモデルで,層を単純に重ねるだけのモデルを指しています。
二行目で,入力をフラットにしています。3行目以降で,作成したインスタンスに2つの層を追加しています。1層目はユニット数が128個で活性化関数がReLUです。2層目はユニット数が10個で活性化関数がsoftmax関数を利用しています。最後の活性化関数をsoftmaxにすることで,出力値は確率のようにみなすことができます。
最適化アルゴリズムの定義
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])モデルインスタンスのcompileメソッドによって,学習に利用する最適化アルゴリズムの詳細を設定できます。optimizer引数でAdamを指定しています。誤差関数はクロスエントロピー,評価関数はaccuracyを設定しています。
学習の実行
history = model.fit(train_images, train_labels, epochs=5,
verbose=1, validation_data=(test_images, test_labels))modelインスタンスのfitメソッドで学習を実行しています。学習とは,ネットワークの重みを学習データに適合(fit)させることを指しています。epochsはバッチサイズの学習を何回繰り返すかを表しています。validation_dataは,評価に利用するデータセットの設定です。
historyという変数に代入することで,以下のように学習過程を視覚化することができます。
#Accuracy
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
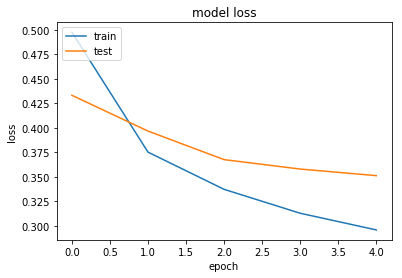
#loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()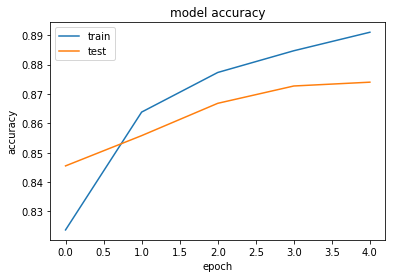
ちなみに,以下のメソッドを利用すれば,作成したモデルの概要を知ることができます。
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
_________________________________________________________________
dense (Dense) (None, 128) 100480
_________________________________________________________________
dense_1 (Dense) (None, 10) 1290
=================================================================
Total params: 101,770
Trainable params: 101,770
Non-trainable params: 0
_________________________________________________________________
評価の実行
score = model.evaluate(test_images, test_labels)
print('Test loss:', score[0])
print('Test accuracy:', score[1])Test loss: 0.3513376784563065
Test accuracy: 0.874上でも評価は行っていますが,改めてscoreに代入します。出力から最終的なlossとaccuracyを読み取れます。約87%の精度が出ました。
予測の実行
predictions = model.predict(test_images)
print(np.argmax(predictions[0]))9訓練に利用したデータに対する予測をしています。一つ目のテストデータは9番目のクラスラベルに属するという出力です。
予測した画像を「自信度の強さ付き」で表す関数を定義します。
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array[i], true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array[i], true_label[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
これらを,3×5のテストデータに関して試してみます。
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions, test_labels)
plt.show()