【超初心者向け】TensorFlowのチュートリアルを読み解く。<その1>



本シリーズでは,ディープラーニングを実装する際に強力な手助けをしてくれる「TensorFlow」についてです。公式チュートリアルを,初心者に向けてかみ砕きながら翻訳していこうと思います。(公式ページはこちらより)
今回はNo.1で,「Keras」編です。その他の記事は,こちらの「TensorFlowの公式チュートリアルを初心者向けに読み解く」をご覧ください。
基本的な流れ
TensolFlowでディープラーニングを実装する流れは,以下のようになります。
●データセットの読み込み
●ネットワークの定義
●最適化アルゴリズムの定義
●学習の実行
●評価の実行
●予測の実行
API
Karasは深層学習をモデリングするための高水準APIです。APIとは,「Application Programming Interface」の頭文字をとったもので,ソフトウェアとプログラムを繋ぐ役割をします。例えば,Twitter APIを利用すればタイムラインをもつアプリを実装できますし,LINE APIを利用すればチャットボットのようなアプリを実装することができます。
つまり,KerasというAPIを使えばTensorFlowの枠組みの中で深層学習モデルを構築することができるのです。
必要なモジュール等の準備
!pip install -q pyyaml構築したモデルはYAML形式で保存します。python上でYAML形式をいじるためにpyyamlをインストールしておきましょう。(今回は使用しません)
import tensorflow as tf
import numpy as np
from tensorflow.keras import layers
import matplotlib.pyplot as plttensorflowとkerasをインポートしましょう。今回は概要を説明するため,layersを使います。
データセットの読み込み
def random_one_hot_labels(shape):
n, n_class = shape
classes = np.random.randint(0, n_class, n)
labels = np.zeros((n, n_class))
labels[np.arange(n), classes] = 1
return labels
data = np.random.random((1000, 32))
labels = random_one_hot_labels((1000, 10))
val_data = np.random.random((100, 32))
val_labels = random_one_hot_labels((100, 10))今回は,データセットを読み込むのではなく,生成します。まずは,教師ラベルをランダムに生成する関数を定義しています。
dataは(1000, 32)のサイズですが,これは「32次元のデータが1000個ある」ことを意味しています。同じように,labelsは「10次元のデータが1000個ある」ことを意味しています。つまり,1つのデータは32次元で,それぞれ10種類のクラスが用意されているということです。そのデータが今回は1000個用意されています。
今回は,データセットを生成しましたので,さきほど入力データの定義も同時に行ってしまいました。流れとは逆行しますが,今回は入力データからデータセットを定義してしまいましょう。
dataset = tf.data.Dataset.from_tensor_slices((data, labels))
dataset = dataset.batch(32)
dataset = dataset.repeat()
val_dataset = tf.data.Dataset.from_tensor_slices((val_data, val_labels))
val_dataset = val_dataset.batch(32)
val_dataset = val_dataset.repeat()先ほど作った「data」と「labels」を利用してdatasetインスタンスを生成しています。dataste.batchでミニバッチ化をしています。dataset.repeatでデータセットを無限個繰り返して生成しています。
ネットワークの定義
model = tf.keras.Sequential()
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))一行目で,kerasのsequentialモデルのインスタンスを生成しています。sequentialモデルは深層学習の中でも最も基本的なモデルで,層を単純に重ねるだけのモデルを指しています。
作成したインスタンスに,3つの層を追加しています。1層目はユニット数が64個で活性化関数がReLUです。2層目は1層目と同じですね。3層目はユニット数が10個で活性化関数がsoftmax関数を利用しています。最後の活性化関数をsoftmaxにすることで,出力値は確率のようにみなすことができます。
最適化アルゴリズムの定義
model.compile(optimizer=tf.train.AdamOptimizer(0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])モデルインスタンスのcompileメソッドによって,学習に利用する最適化アルゴリズムの詳細を設定できます。optimizer引数でAdamを指定しています。誤差関数はクロスエントロピー,評価関数はaccuracyを設定しています。
学習の実行
history = model.fit(dataset, epochs=10, steps_per_epoch=30,
validation_data=val_dataset,
validation_steps=3)modelインスタンスのfitメソッドで学習を実行しています。学習とは,ネットワークの重みを学習データに適合(fit)させることを指しています。epochsはバッチサイズの学習を何回繰り返すか,steps_per_epochは1エポックごとの学習ステップ数を表しています。最後の引数2つは,評価に利用するデータセットの設定です。
historyという変数に代入することで,以下のように学習過程を視覚化することができます。
#Accuracy
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
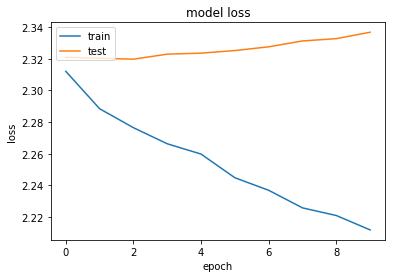
#loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()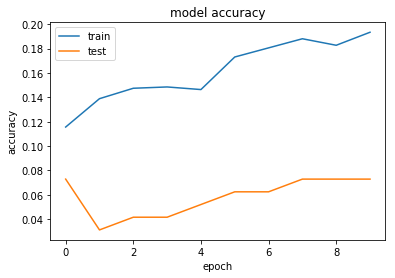
ちなみに,以下のメソッドを利用すれば,作成したモデルの概要を知ることができます。
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) multiple 2112
_________________________________________________________________
dense_1 (Dense) multiple 4160
_________________________________________________________________
dense_2 (Dense) multiple 650
=================================================================
Total params: 6,922
Trainable params: 6,922
Non-trainable params: 0
_________________________________________________________________
評価の実行
score = model.evaluate(val_dataset, steps=30)
print('Test loss:', score[0])
print('Test accuracy:', score[1])Test loss: 2.2960101127624513
Test accuracy: 0.07853403上でも評価は行っていますが,改めてscoreに代入します。出力から最終的なlossとaccuracyを読み取れます。
予測の実行
result = model.predict(data, batch_size=32)訓練に利用したデータに対する予測をしています。