
【超初心者向け】パーセプトロン学習規則による2値分類をpythonで分かりやすく実装してみた。



今回は,scikit-learnなどの既成ライブラリに頼らずにパーセプトロン学習規則に基づく二値分類を実装していこうと思います。また,本記事はpython実践講座シリーズの内容になります。その他の記事は,こちらの「Python入門講座/実践講座まとめ」をご覧ください。
データセット
今回は,パーセプトロン2値分類のアルゴリズムが「線形2値分類可能」な場合に限り収束するという性質の制限があるため,scikit-learnのメソッドを利用して線形分離可能なデータセットを作成します。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
x_train, t_train = make_blobs(random_state=8, n_samples=50, n_features=2, cluster_std=1.5, centers=2)
N = x_train.shape[0] # サンプル数
D = x_train.shape[1] # 特徴数
ones = np.ones(N)
x_train = np.hstack([np.array([ones]).T, x_train])
t_train = np.where(t_train==0, -1, t_train)plt.scatter(x_train[:, 0], x_train[:, 1], marker='o', c=t_train)
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")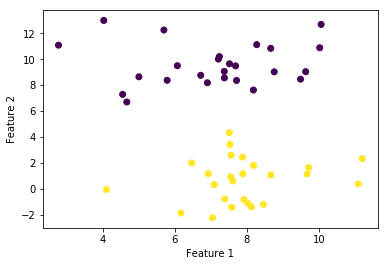
重みのバイアス項を作るために,すべての要素が1の行列をx_trainの左側からくっつけます。また,t_trainは,x_trainのラベルとして与えられますが,デフォルトでは$\{ 0,1 \}$の二値になっており,$\{ -1, 1 \}$の二値にするためにnumpyのwhereメソッドを利用しています。
コード
以下では,まず部分的にコードの解説をした後に,全体のコードをお伝えしたいと思います。
識別関数の定義
def Phi(w, x):
phi_x = w.T @ x
if phi_x > 0:
disc = 1
else:
disc = -1
return [phi_x, disc]今回の識別関数は,重みパラメータとデータの内積で与えることにします。つまり,単項式回帰と同様に識別面は直線になるということです。
重みの最適化
def OptimalWeight(w, x, t, c):
phi_x, disc = Phi(w, x)
if disc * t > 0:
w_opt = w
else:
w_opt = w + (c * t * x)
return [w_opt, disc*t]最急降下法のアイディアにより,識別が正しく行われていない時に限り,ベクトルxを重みベクトルに足し合わせることで,識別面に垂直な方向(つまりxの方向)に方向ベクトルを回転させます。
メイン部分
N = x_train.shape[0]
D = x_train.shape[1]
w_init = np.zeros(D).T
w_opt = w_init
Disc = np.zeros(N)
iter = 100
for i in range(iter):
for n in range(N):
w_opt, Disc[n] = OptimalWeight(w_opt, x_train[n, :], t_train[n], c=0.5)
if all([e>0 for e in Disc]):
breakNとDを新しく取得した後に,重みの初期値を設定しています。今回は,単純に全て0に設定しました。続いて,識別関数の出力(正負)を保持するための箱(Disc=Discrimination)を作ります。繰り返しの部分では,適当に更新回数を100回にしました。もし,すべての識別関数の出力が正の場合は,ループから抜けるように処理してあります。また,適当に学習係数は0.5にしました。
グラフ出力の準備
# w_1*x_1 + w_2*x_2 + w_3*x_3 = 0
# x_3 = -(w_1*x_1 + w_2*x_2) / w_3
xlist = np.arange(np.min(x_train[:, 1]), np.max(x_train[:, 1]), 0.1)
ylist = -(w_opt[0]*1 + w_opt[1]*xlist) / w_opt[2]コメントでも記してありますが,$w_1 x_1 + w_2 x_2 + w_3 x_3 = 0$が識別面の関数なので,$x_3 = -\frac{w_1 x_1 + w_2 x_2}{w_3}$と変形することによりxlistに対する出力であるylistを得ることができます。
グラフ出力
plt.plot(xlist, ylist)
plt.scatter(x_train[:, 1], x_train[:, 2], marker='o', c=t_train)
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()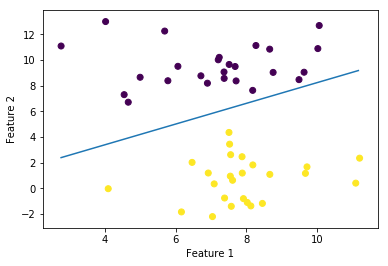
考察
今回は,パーセプトロン学習規則に基づいて二値分類を試みました。ニューラルネットの基礎となる考え方ですので,ぜひしっかりとおさえておきたいところです。学習結果を視覚的に確認すると,分類面がやや上よりになっていることが分かります。これは,一度収束してしまえばそこから動かない(今回の場合はforループから抜け出す)というパーセプトロン学習規則の性質をよく表しているものです。このような欠点を補うために生み出された手法が,かの有名なサポートベクトルマシン(SVM)です。
もし理論にモヤモヤがあれば

こちらの参考書は,誰もが挫折しかけるPRMLよりも平易に機械学習全般の手法について解説しています。おすすめの1冊になりますので,ぜひお手に取って確認してみてください。
全体のコード
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
def Phi(w, x):
phi_x = w.T @ x
if phi_x > 0:
disc = 1
else:
disc = -1
return [phi_x, disc]
def OptimalWeight(w, x, t, c):
phi_x, disc = Phi(w, x)
if disc * t > 0:
w_opt = w
else:
w_opt = w + (c * t * x)
return [w_opt, disc*t]
x_train, t_train = make_blobs(random_state=8,
n_samples=50,
n_features=2,
cluster_std=1.5,
centers=2)
N = x_train.shape[0]
D = x_train.shape[1]
ones = np.ones(N)
x_train = np.hstack([np.array([ones]).T, x_train])
t_train = np.where(t_train==0, -1, t_train)
plt.scatter(x_train[:, 1], x_train[:, 2], marker='o', c=t_train)
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
N = x_train.shape[0]
D = x_train.shape[1]
w_init = np.zeros(D).T
w_opt = w_init
Disc = np.zeros(N)
iter = 100
for i in range(iter):
for n in range(N):
w_opt, Disc[n] = OptimalWeight(w_opt, x_train[n, :], t_train[n], c=0.5)
if all([e>0 for e in Disc]):
break
xlist = np.arange(np.min(x_train[:, 1]), np.max(x_train[:, 1]), 0.1)
ylist = -(w_opt[0]*1 + w_opt[1]*xlist) / w_opt[2]
plt.plot(xlist, ylist)
plt.scatter(x_train[:, 1], x_train[:, 2], marker='o', c=t_train)
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()












