
【超初心者向け】日本語の文章をpythonでコーヒーの味覚指標に変換。



今回は,Pythonで簡単な感情分析をする方法をお伝えしていこうと思います。数年前に流行った感情分析ですが,今でも進化したword2vec(doc2vec)を利用してより高精度に行うことが出来るようになっています。
本記事はpython実践講座シリーズの内容になります。その他の記事は,以下の「Python入門講座/実践講座まとめ」をご覧ください。

感情分析とは
感情分析を簡単に噛み砕くと,文章から人間の感情を推定する問題のことを指します。使用言語は問いませんが,やはり英語に対する研究例が多いです。日本語は英語に比べるとまだまだ発展途上な面はあるのですが,近年のword2vecモデルの発展により,より高精度な感情分析が可能になっています。
word2vecとは?
深層学習の発展に伴い,機械学習の分野では単語や文章を分散表現(ベクトル)で表そうという動きが出てきました[1]。分散表現で表すことにより,単語を数値として扱うことが出来るようになります。例えば,有名な例ではありますが
king – man + woman = queen
のように,私たちが単語の裏で意識している意味を数値として表すことができるのです。また,ベクトル(行列)として扱うことができると,深層学習と非常に相性が良くなります。逆に言えば,数値として表現されていないデータに対しては,深層学習を適用することは難しいです。
このように,単語を分散表現に直すことができれば嬉しいことがたくさんあります。しかしそもそも,分散表現自体はどのようにして獲得するのでしょうか。そのための手法の1つが,「word2vec」です。
となりませんか?少なくとも私はなりました。これは「word to vector」を省略した形として「word2vec」となっているようです。「I love you」を「I love u」と省略するのと同じようなものですね。さて,最近ホットな分散表現獲得モデルとしては,BERT[2]が挙げられます。BERTを利用すれば,従来は単語そのものに着目して分散表現に変換していたところを,前後の文脈を考慮して分散表現を獲得することが可能になります。
学習済みモデルの利用
BERTの欠点として挙げられるのは,必要とする学習データと学習時間の長さです。とてもではありませんが,私たちの〝ノートパソコン〟では学習に時間がかかって仕方ありません。そこで私たちが活用できるのが,学習済みBERTです。こちらのURLからソースをダウンロードできます。
今回は,背伸びせずに単純なword2vecを試してみたいと思います。こちらのURLから,作者のGitHubレポジトリにアクセスしてください。下にスクロールしていくと「Japanese(w)」が見つかると思いますので,クリックしてダウンロードしてください。ちなみに,(w)はword2vecモデル,(f)はfastTextモデルのことを表しています。
ダウンロードしたファイルは,これからコードを実行するディレクトリに置いておきましょう。Colaboratoryを使用している方は,少し時間がかかりますがアップロードしておきましょう。
感情分析の流れ
鋭い指摘ですね。たとえ,単語や文章を分散表現に直すことができても,それらが感情と結びつかなければ意味がありません。そこで,今回は日本語感情表現辞書を利用して単語と感情を結びつけることにしました。こちらのURLから分類されたエクセルファイルをダウンロードしてください。今回利用するのは,一番最初のタブの「感情分類」だけです。
さらに,今回は「コーヒーの味覚指標」と感情を表す単語を結びつける必要があります。ここは,人手での記述が必要になる場面です。そこで,今回は私が,word2vecモデルの辞書にない単語を考慮して,「感情を表す単語(漢字)↔︎コーヒーの味覚指標」の対データを作成しました。
 利用する教師データ
利用する教師データこれらのデータを利用して,簡単な全結合の深層学習モデルで学習を進めていきます。
学習
ここからは,簡単なpythonの実装も交えながら学習の方法をお伝えしていこうと思います。
学習済みword2vecの設置
上でダウンロードした学習瑞word2vecモデルのデータがあるディレクトリに移動しましょう。colaboratoryを利用している方は「アップロード」より「ja」フォルダに入っているファイルを全てcolaboratory上に用意しましょう。
必要なライブラリ等のインポート
import pandas as pd
import gensim
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch import optim
import torch.utils as utils
from torchvision import datasets, transforms今回は,日本語感情表現辞書の読み取りのためにpandas,学習済みword2vecの利用のためにgensimを利用します。それ以下は,深層学習に利用するためのライブラリです。
日本語感情表現辞書の読み込み
df_emotion = pd.read_csv('means.csv', sep=',', encoding='utf-8', index_col=False, header=None)
emotions = list(df_emotion[1])[1:]感情分類タブの二列目を読み込んでいきます。これらの単語(漢字)を私の方で微調整したのが先ほどの学習データに当たります。
学習データの作成
kaori = ["誇","感動","喜","緊張","穏","謝罪","憐"] #香り
nigami = ["悲","鬱","嫌","怒","恨","恐","怖","厭","憎","情"] #苦味
sannmi = ["寂","切","憂鬱","恥","焦","悔","気","躊躇","懸念","苦"] #酸味
amami = ["安", "感謝","祝","怠","難色","失望","尊"] #甘み
koku = ["驚","幸","呆","嫉妬","悩","辛","侮辱","困"] #コク
konomi = ["楽","親","快感","好","興奮","願","遺憾"] #好みかなり恣意的ではありますが,このような教師データを利用していきます。
と思われるかもしれませんが,今回は簡単な実験ですのでご勘弁願います。
word2vecモデルの準備
model_ja = gensim.models.Word2Vec.load("ja.bin")先ほど用意した学習済みモデルを読み込みましょう。jaフォルダが置かれているディレクトリにいる方は”ja.bin”を「”./ja/ja.bin”」と変更しましょう。
実は,ここでコケる場合があります。というのも,学習済みモデルで指定されているgensimとお使いのgensimのバージョンの互換性がなければエラーを吐いてしまいます。colaboratoryで実行されている方は,gensimが最新版でない可能性があるため特に注意です。私の場合は「3.6.0」がデフォルトでインストールされていて,これでは実行ができませんでした。arrayをreshapeできないと怒られてしまいました。
Out:
cannot reshape array of size 7602156 into shape (50108,300)print(gensim.__version__)Out:
'3.6.0'
そこで,gensimをアップデートしたところ,うまく通りました。
!pip install -U gensim
print(gensim.__version__)Out:
'3.8.0'
教師データのリスト化
kaori_score = np.array([model_ja[kaori[i]] for i in range(len(kaori))])
nigami_score = np.array([model_ja[nigami[i]] for i in range(len(nigami))] )
sannmi_score= np.array([model_ja[sannmi[i]] for i in range(len(sannmi))] )
amami_score= np.array([model_ja[amami[i]] for i in range(len(amami))] )
koku_score= np.array([model_ja[koku[i]] for i in range(len(koku))] )
konomi_score= np.array([model_ja[konomi[i]] for i in range(len(konomi))])
scores = np.concatenate([kaori_score, nigami_score, sannmi_score, amami_score, koku_score, konomi_score], axis=0)教師データと学習済みモデルを利用して,深層学習モデルに読み込ませるリストを作成します。
print(scores.shape)Out:
(49, 300)今回は,単語(漢字)数が49個,分散表現の次元が300次元です。
正解ラベルの作成
a = [1,0,0,0,0,0]
b = [0,1,0,0,0,0]
c = [0,0,1,0,0,0]
d = [0,0,0,1,0,0]
e = [0,0,0,0,1,0]
f = [0,0,0,0,0,1]
target = []
for i in range(len(kaori_score)):
target.append(a)
for i in range(len(nigami_score)):
target.append(b)
for i in range(len(sannmi_score)):
target.append(c)
for i in range(len(amami_score)):
target.append(d)
for i in range(len(koku_score)):
target.append(e)
for i in range(len(konomi_score)):
target.append(f)先ほど作成したリストと,感情の正解を表すラベルを作成します。こうすることで,深層学習のネットワークが出力するのは「6つの味覚指標のうちどこに単語(漢字)がどこに属するか」という確率になります。ラベルの意味づけを分かりやすくするために,原始的なコーディングにしています。もっと簡単には,単位行列を生成すればOKです。(型がndarrayになる点に注意です。)
target = np.eye(3)
GPUの確認(オプション)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")GPUが利用できる環境にある方は,使ってみましょう。今回は,計算量が非常に少ないため,基本的にGPUは不必要です。今回はGPU操作の練習も兼ねて実装を行なっていきたいと思います。
自作データセットクラスの定義
class MyDataset(torch.utils.data.Dataset):
def __init__(self, data, label, transform=None):
self.transform = transform
self.data = data
self.data_num = len(data)
self.label = label
def __len__(self):
return self.data_num
def __getitem__(self, idx):
if self.transform:
out_data = self.transform(self.data)[0][idx]
out_label = self.label[idx]
else:
out_data = self.data[idx]
out_label = self.label[idx]
return out_data, out_labelこちらの記事でもお伝えしているように,pytorchにデフォルトで用意されているデータセット以外を利用する場合は,基本的に自分のデータセットクラスの定義をする必要があります。今回は,非常に単純なクラスを実装しています。
transformの定義
transform = transforms.Compose([transforms.ToTensor()])データセットクラスに渡すtransformの定義をしていきます。今回は,単純にテンソル化するだけの処理を定義しておけばOKです。画像などを扱う際には,サイズを調整したり正規化をしたりする必要があります。
datasetの定義
dataset = MyDataset(scores, target, transform)先ほど定義した単語ごとのスコア(scores),ラベル(target),前処理(transform)を自作データセットクラスに渡してインスタンスを作成します。このインスタンスをdataloaderに変換することで,pytorchでは深層学習を便利に実行することができます。
dataloaderの定義
dataloader = torch.utils.data.DataLoader(dataset, batch_size=7, shuffle=True)Dataloaderはデータセットをバッチサイズの塊で繰り返し返してくれるような役割を果たしてくれます。今回は,データセット数が49ということで,バッチサイズは適当に7に定めました。計算量が少ないため,バッチサイズは気にしなくてもOKです。
ネットワークの定義
class SentimentNet(nn.Module):
def __init__(self):
super(SentimentNet, self).__init__()
self.fc1 = nn.Linear(300, 200)
self.bn1 = nn.BatchNorm1d(200)
self.fc2 = nn.Linear(200, 100)
self.bn2 = nn.BatchNorm1d(100)
self.fc3 = nn.Linear(100, 6)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.bn1(x)
x = F.relu(self.fc2(x))
x = self.bn2(x)
x = F.softmax(self.fc3(x))
return x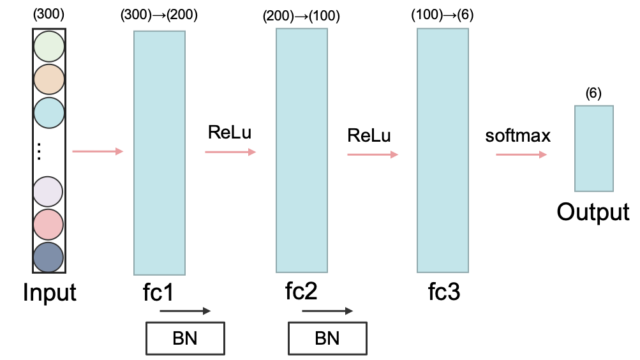 SentimentNetの構造
SentimentNetの構造ネットワークは非常にシンプルな構造としました。全結合を3層重ねて,バッチ正規化も取り入れました。ちなみに,FCは「Fully Connected」の略で全結合,BNは「Batch Normarization」の略でバッチ正規化を表しています。
モデルのインスタンス化
model = SentimentNet().to(device)先ほど定義したネットワークをインスタンス化します。
パラメータ設定
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
num_epochs = 100今回の誤差関数は教師ラベルとsoftmaxの出力の二乗誤差です。最適化にはSGDを利用して,学習率は0.01で固定しました。エポック数は100です。
学習の実行
model.train()
loss_list = []
for i in range(num_epochs):
losses = []
for x, t in dataloader:
x = x.to(device)
t = t.to(device)
model.zero_grad()
y = model(x)
loss = criterion(y.float(), t.float())
loss.backward()
optimizer.step()
losses.append(loss.cpu().detach().numpy())
loss_list.append(np.average(losses))
print("EPOCH: {} loss: {}".format(i+1, np.average(losses)))Out:
EPOCH: 1 loss: 0.13691553473472595
EPOCH: 2 loss: 0.12982188165187836
EPOCH: 3 loss: 0.12495331466197968
EPOCH: 4 loss: 0.11738365888595581
EPOCH: 5 loss: 0.10869894176721573
EPOCH: 6 loss: 0.09959430992603302
EPOCH: 7 loss: 0.09877688437700272
EPOCH: 8 loss: 0.08762024343013763
EPOCH: 9 loss: 0.08228349685668945
EPOCH: 10 loss: 0.08159802854061127
...実際に学習している様子が分かります。
ロスの減少過程の描画
plt.figure()
plt.plot(range(num_epochs), loss_list, 'r-', label='train_loss')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.grid()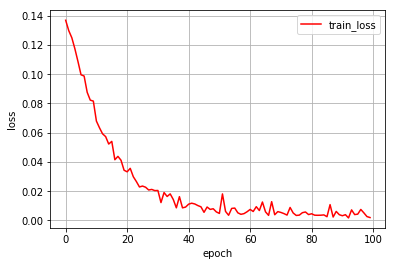
過学習気味かもしれません。学習率をもう少し下げた方がいいかもですね。
定性的な評価実験
今回は,簡単な2つのレビュー文を味覚指標に変換してみたいと思います。あくまでも定性的な実験です。今回は,ValidationとTestは行いませんでした。対象とする文章は,以下の2つとします。
文章A:個人的に男の子の友情の話が大好きです
文章B:人物が悲しんでいる時にはいつの間にか私の目からも涙が零れ落ちています
これらを,今回は人手で単語に分割していきます。文章に含まれる単語の平均ベクトルを今回は図示してみたいと思います。
vec1 = model_ja["個人"]
vec2 = model_ja["男"]
vec3 = model_ja["友情"]
vec4 = model_ja["好物"]
vec5 = model_ja["凄"]
vec6 = model_ja["好"]
vec = torch.tensor((vec1+vec2+vec3+vec4+vec5+vec6)/6)まずは文章Aの平均分散表現を計算します。この分散表現を学習済みモデルに通すことで,6つの指標の確率値が出力されます。
model.eval()
sentiment_A = model(vec.unsqueeze(0).to(device))
print(sentiment_A)tensor([[0.0476, 0.0970, 0.0858, 0.2150, 0.1867, 0.3678]], device='cuda:0',
grad_fn=<SoftmaxBackward>)
ここで,レーダーチャート作成のために,最大値が5になるようにテンソルを正規化します。
sentiment_A = (sentiment_A / torch.max(sentiment_A))*5print(sentiment_A)Out:
tensor([[0.6475, 1.3190, 1.1666, 2.9224, 2.5374, 5.0000]], device='cuda:0', grad_fn=<MulBackward0>) 文章Aの味覚指標
文章Aの味覚指標
文章Bについても同じ操作を施しましょう。
vec_1 = model_ja["登場"]
vec_2 = model_ja["人物"]
vec_3 = model_ja["悲"]
vec_4 = model_ja["時"]
vec_5 = model_ja["間"]
vec_6 = model_ja["私"]
vec_7 = model_ja["目"]
vec_8 = model_ja["涙"]
vec_9 = model_ja["雫"]
vec_10 = model_ja["落"]
vec2 = torch.tensor((vec_1+vec_2+vec_3+vec_4+vec_5+vec_6+vec_7+vec_8+vec_9+vec_10)/10)
sentiment_B = model(vec2.unsqueeze(0).to(device))
sentiment_B = (sentiment_B / torch.max(sentiment_B))*5print(sentiment_B)tensor([[1.1377, 1.7736, 5.0000, 3.4021, 2.0418, 1.5875]], device='cuda:0', grad_fn=<MulBackward0>) 文章Bの味覚指標
文章Bの味覚指標
2つをまとめて見てみます。
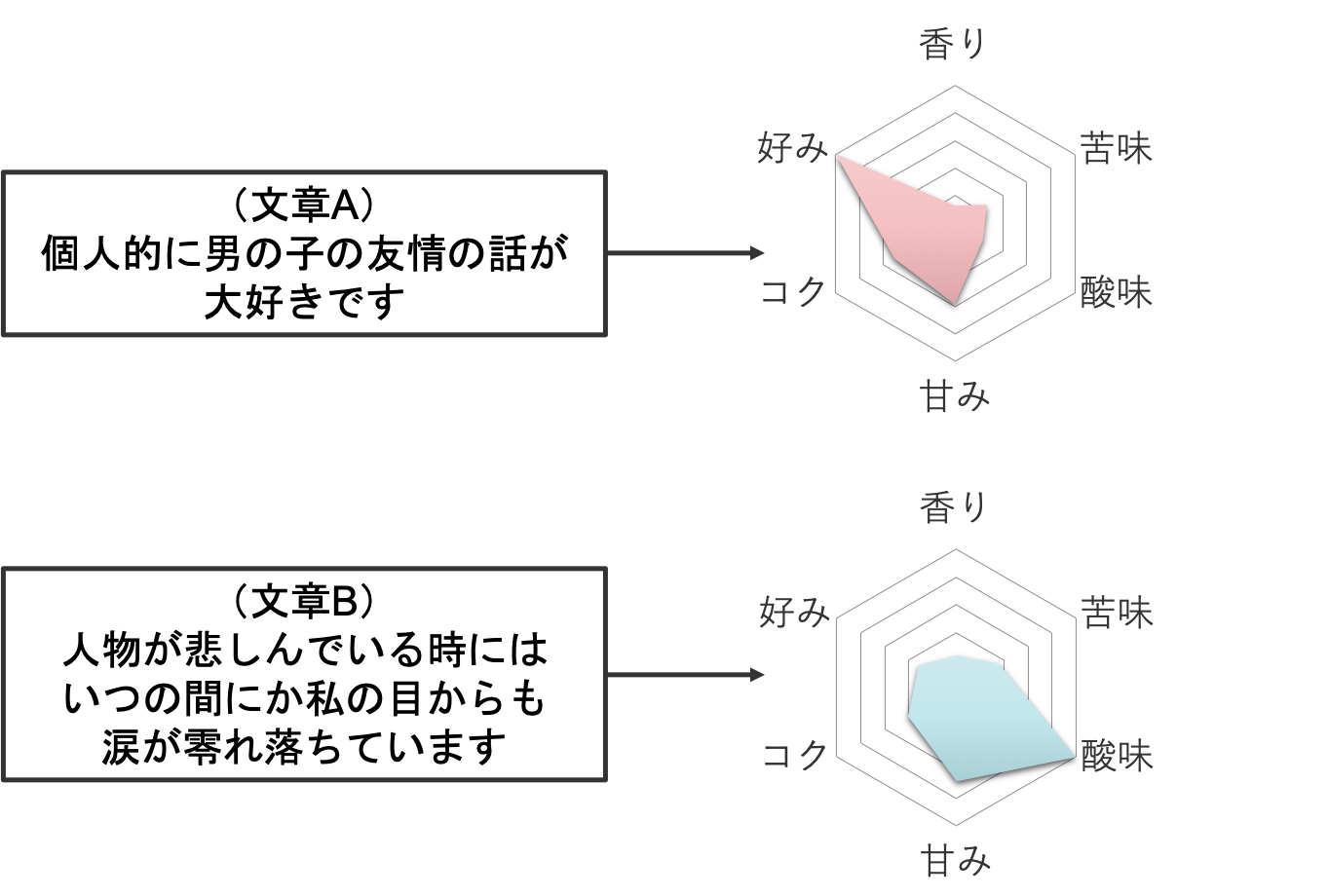 文章Aと文章Bの実験結果比較
文章Aと文章Bの実験結果比較なかなか妥当ではないでしょうか。文章Aは「好み」という指標が突出していますが,実際にそのような文章だと感じられます。また,文章Bも酸味を感じられる文章であることは確かです。一方で,文章Bは苦味や香り,コクといった部分にもある程度の要素は感じられるため,教師データのさらなる拡充や過学習気味のネットワークの見直しが必要そうです。
まとめ
意外と妥当な結果がでて面白かったです。今後は,word2vec以外の分散表現獲得モデルを利用したり,seq2seqで文章を他の表現に変換することで,レーダーチャート以外で味覚指標の可視化等ができれば面白いと思います。
[1] https://arxiv.org/abs/1405.4053
[2] https://arxiv.org/abs/1810.04805
[3] 星野裕, 花村和男, and 広瀬幸雄. “コーヒーの嗜好に関する工学的解明.” 生産管理 11.2 (2005): 27-36.











