
【サーベイまとめ】係り受け解析(Dependency Parsing)とは?ニューラルネットワークとの関係も簡潔に説明します。

この記事では,研究のサーベイをまとめていきたいと思います。ただし,全ての論文が網羅されている訳ではありません。また,分かりやすいように多少意訳した部分もあります。ですので,参考程度におさめていただければ幸いです。
間違えている箇所がございましたらご指摘ください。随時更新予定です。他のサーベイまとめ記事はコチラのページをご覧ください。
係り受け解析とは?
一般に,言語処理を行う時には「形態素解析」「構文解析」「意味解析」という三段階に分けて考えることが多いです。形態素解析では,単語の品詞や時制などを推定します。構文解析では,形態素解析の結果を用いてさらに細かな構造(主語・述語等)を推定していきます。最後に,文章の意味を推定していきます。
係り受け解析とは,「構文解析」を行う上で各単語の構成要素(この単語は動詞句の中に含まれる…等)をもとに構造化していくのではなく,各単語の依存関係に着目して構造化する手法になります。
係り受け解析の仮定
文献[1]では,係り受け解析には3つの仮定があるとしています。
1.循環閉路がない
2.各単語の流入エッジは1つ
3.連結グラフである
ニューラルネットワーク以前
文献[2]では,係り受け解析に関しての基本的な手法(arc-eager)が提案されています。具体的には,Input(Buffer)からStackに単語を文頭から入れていき,「BufferからStackに移動」「BufferとStackの先頭を接続」「StackとBufferの先頭を接続」「Stackの先頭を取る」の操作を繰り返すことで,依存関係を解析していくという手法です。
このようなモデルは「Shift-Reduce」と呼ばれています。arc-eagerのみならず,他にも多くのモデルが考案されました[3]。ちなみに,arc-eagerはard-standardの拡張とも捉えられ,木構造構築の柔軟さから,当時(2011年頃)のSOTA(State-Of-The-Art)を達成していました。
ニューラルネットワークの利用
依存関係を推定するということは,何かしらのルールに基づいて行われるということを指します。つまり,私たち設計者の恣意性が含まれてしまう可能性があります。そこで,ニューラルネットワークを利用した推定に関わる研究が数多く行われています。
最もベーシックな方法として,文献[4]で挙げられているような方法があります。
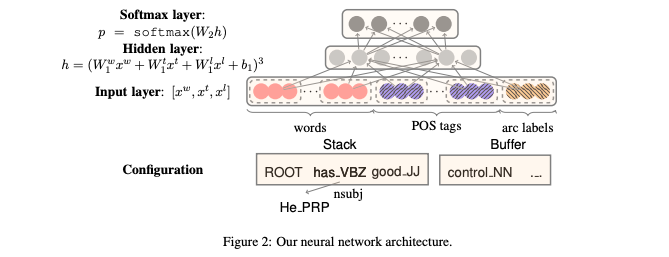 出典:文献[4]
出典:文献[4]こちらの方法の簡単な説明としては,単語,品詞タグ,枝ラベルのEmbedding$[x^w, x^t, x^l]$を入力として与えます。ネットワーク内では,それらの重み付けにバイアスを加えたものを三乗してソフトマックス層に通します。そうすることで得られる出力が係り受けのスコアとなり,そのスコアに基づいて依存関係を推定していくという流れになります。
また,loss関数は以下のように与えられます。
$$
L(\theta) = -\sum_i \log p_i + \frac{\lambda}{2}\| \theta\|^2
$$
ニューラルネットワークを利用した新しい手法としては,双方向LSTMを利用した「Deep Biaffine parser」[5]が挙げられます。
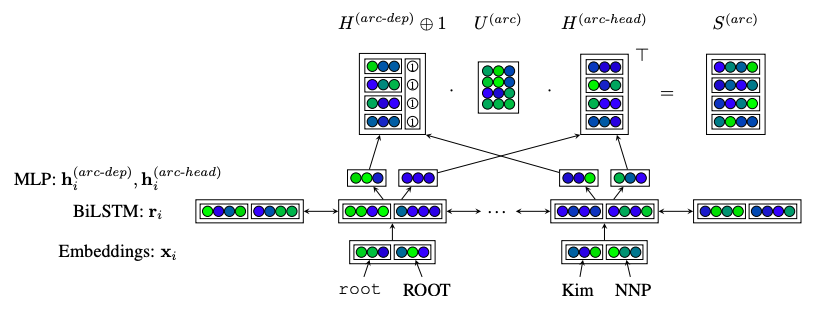 出典:文献[5]
出典:文献[5]簡単な流れとしては,以下のようになります。
1. 単語とタグからEmbeddingを生成
2. Embeddingを多層パーセプトロン(MLP)によって次元削減
3. Biaffine変換を施す
次元削減することで,無駄な情報を削ぎ落としています。しかし,一方で,オーバーフィッティングのリスクも高まります。簡単に数式で表してみると,以下のようになります。
\begin{eqnarray}
s_{i, j} &=& h_i^{{head}^T}Uh_j^{dep} + h_i^{{head}^T}u \\
h_i^{head} &=& MLP^{head}(r_i) \\
h_j^{dep} &=& MLP^{dep}(r_j)
\end{eqnarray}
・$w_i$: 単語
・$x_i$: $w_i$のEmbedding
・$r_i$: $x_i$をbiLSTMに通した出力
$s_{i, j} = h_i^{{head}^T}Uh_j^{dep} + h_i^{{head}^T}u$の解釈を最後に補足しておきます。第一項目は,$w_i$と$w_j$の係り受けやすさを表しています。第二項目は,$w_i$の主辞になりやすさを表しています。足し合わせることで,$s_{i,j}$は$w_j$から$w_i$の係り受けやすさを表しています。
今後の課題としては,文献[5]中で示されている結果で,ラベル付きの精度とラベルなしの精度で結果が大きく異なっているのですが,そのギャップを埋めることだとしています。また,未知語への対応も課題として挙げられています。
[1]https://web.stanford.edu/~jurafsky/slp3/13.pdf
[2]Nivre, Joakim. “Incrementality in deterministic dependency parsing.” Proceedings of the Workshop on Incremental Parsing: Bringing Engineering and Cognition Together. Association for Computational Linguistics, 2004.
[3]Goldberg, Yoav, and Joakim Nivre. “A dynamic oracle for arc-eager dependency parsing.” Proceedings of COLING 2012. 2012.
[4]Chen, Danqi, and Christopher Manning. “A fast and accurate dependency parser using neural networks.” Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014.
[5]Dozat, Timothy, and Christopher D. Manning. “Deep biaffine attention for neural dependency parsing.” arXiv preprint arXiv:1611.01734 (2016).













文献[2]がPage not foundになるので、正確なところが書けないのですが、図を見た感じではDanqi Chenの「A Fast and Accurate Dependency Parser using Neural Networks」(2014)だろうと思うので。もし、そうなら、ちゃんとarc-standardアルゴリズム(たとえばNivre 2004)を説明してからでないと、どうしてこの図で「品詞」から「係り受け」が推定できるのかサッパリ理解できないと思うのです。
安岡 様
ご指摘誠にありがとうございます。
文献に関しては,修正済みでございます。
arc-standard, arc-eagerについての簡単な内容を加えておきました。
一方で,まだ自分の理解が及ばない箇所もあり,十分な記述ができておりません。
ニューラルネットを使うにしても,それの何が嬉しいのか,どのような問題を解決しているのか,既存の手法のどこに対応しているのかを意識しなくてはならないと感じました。
十分に時間を使える際に,また立ち戻ってみたいと思います。
「Universal Dependencies」というキーワードで探してみると、このあたり、色々と面白い研究が見つかると思います。ぜひ頑張って、調べて書いてみて下さいね。
恐れ入ります。ご教授ありがとうございます。
このようにFBいただけることは,個人ブログにて少しずつでもアウトプットを続けていてよかったと感じる瞬間です。
精進したいと思います。