
【超初心者向け】ドラム採譜論文要約「Bayesian Drum Transcription Based on Nonnegative Matrix Factor Decomposition with a Deep Score Prior」

この記事では,研究のサーベイをまとめていきたいと思います。ただし,全ての論文が網羅されている訳ではありません。また,分かりやすいように多少意訳した部分もあります。ですので,参考程度におさめていただければ幸いです。
間違えている箇所がございましたらご指摘ください。随時更新予定です。他のサーベイまとめ記事はコチラのページをご覧ください。

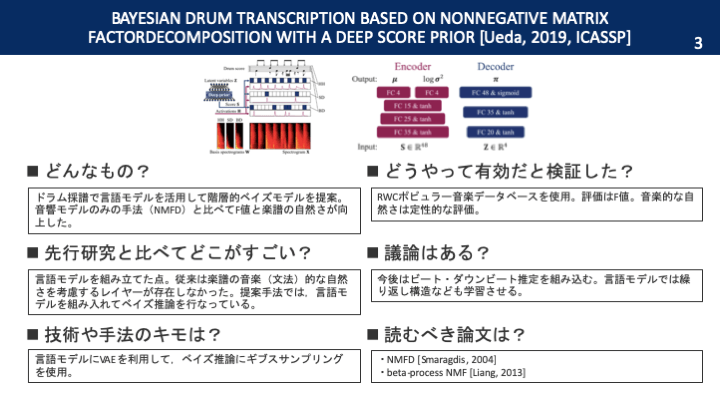
本論文を一枚の画像で
要旨
ドラム採譜の強力な手法としてNMFDが挙げられます。しかし,NMFDでは音楽的に不自然な楽譜を出力してしまう場合があります。そこで,この論文では音楽的な自然さを保証する言語モデルを導入してNMFDと組み合わせる階層的ベイズモデルを考案しています。
導入
音楽情報処理(認識・生成でいうところの特に認識)では,採譜というタスクが非常に重要です。ドラムという楽器に焦点を当てた場合,多くの研究では音楽のベースとなる「バスドラ(BD)」「スネア(SD)」「ハイハット(HH)」を扱っています。さらに,音楽自動採譜ではピアノロール形式(オンセットとオフセットの情報)にすることが行われるため,本当の意味での楽譜には変換されていないという問題があります。私たちが実際に目にするのは楽譜であるのにも関わらず,ピアノロール形式から楽譜に書き起こす作業(リズム採譜)に関する研究はあまり行われていません。
採譜タスクでは,NMFという手法がよく用いられます。しかし,基底行列とアクティベーション行列の積では表現力が乏しいため,ドラム採譜においてはNMFをスペクトログラムとアクティベーション行列の畳み込み積に拡張したNMFDが用いられることが多いです。
スペクトログラムにNMFDをかけた後は,アクティベーション行列のピークピッキングや閾値処理でオンセットとオフセットを求めます。しかし,これらの処理の設定は自明でないことが多く,また単純すぎる操作であることから敬遠されることもあります。beta-process NMFは,オンセットとオフセットの情報をもNMFの枠組みで扱おうとするモデルです。
ドラム自動採譜では,昔から「分類」や「RNN」を利用した手法が試されてきました。しかし,音楽的に自然な楽譜というのは生成されていません。そこで,音楽自動採譜では言語モデルを取り入れる試みがなされてきました。具体的には,隠れマルコフモデル(HMM)やRNN等を利用する研究が盛んです。しかし,シンボリック(離散的)な言語モデルと連続的な音響モデルをどのように統合するかという点に関しては,まだ課題が残っています。
提案手法
まず最初に,音楽信号STFTをかけて振幅スペクトログラムを得ます。次に,振幅スペクトログラムにHPSSを用いて調波音と打楽器音を分離します。続いてNMFDをかけるのですが,KLダイバージェンス基準で近似するため,近似スペクトログラムにポアソン分布を仮定します。すると,共役事前分布として基底行列とアクティベーション行列にガンマ分布を仮定すればよいです。また,オンセット・オフセットの情報は二値ですので,ベルヌーイ分布を仮定します。そして,ベルヌーイ分布のパラメータを言語モデルの出力とします。
あとは,スペクトログラムが与えられた上でパラメータをギブスサンプリングを用いてベイズ推論していくだけです。
実験
【データベース】
・RWCポピュラー音楽データベース
・30秒ごとのセグメントのうち2つめを使用
・HH・SD・BDが使用されている64ピースを使用
【前処理】
・アノテーションを利用して1小節ごとに分割
・サンプリング周波数:44.1kHz
・STFT幅:2048 points
・シフト幅:441 points
・NMFDの基底はRWCの楽器音データから抽出
・VAEはJPOPとビートルズの楽曲から1小節ずつ学習
・ピークピッキングの閾値は振幅の最大値の0.3倍を採用
【評価】
・オンセットのズレは50msまで許容
・F値で評価
・音楽的な自然さは定性的な評価
評価
NMFD onlyに比べて,言語モデルを組み込んだ提案手法の方がF値はほとんどの場合高かったです。楽譜の見やすさも,定性的な有効性が確認されました。
今後の課題
ビート推定とダウンビート推定も行うことで,統一的な枠組みでドラム採譜を行えるようにすることを目指します。他にも,ドラムの繰り返し構造などを言語モデルに学習させることも考えられます。
まとめ
ドラム採譜で言語モデルを組み込んだ初の階層ベイズモデルでした。
Ueda, Shun, et al. “Bayesian Drum Transcription Based on Nonnegative Matrix Factor Decomposition with a Deep Score Prior.” ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019.













