
【超初心者向け】ドラム採譜論文要約「Towards multi-instrument drum transcription」

この記事では,研究のサーベイをまとめていきたいと思います。ただし,全ての論文が網羅されている訳ではありません。また,分かりやすいように多少意訳した部分もあります。ですので,参考程度におさめていただければ幸いです。
間違えている箇所がございましたらご指摘ください。随時更新予定です。他のサーベイまとめ記事はコチラのページをご覧ください。

本論文を一枚の画像で

要旨
多くのドラム採譜研究は「HH」「SD」「BD」の3パートしか扱っていない。本論文は,より多くのパートを扱えるようにするために大規模な合成データセットを作成し,学習済みモデルを公開する初めての試み。
導入
「HH」「SD」「BD」の3パートが扱われる背景には,出現頻度が高いこととリズムのベースを築いていることが理由として挙げられる。それ以外を扱おうとすれば,データ数が少ないという問題に直面する。そこで,本論文ではドラムパートを8種類/18種類に分類して,1つのネットワークを学習する。モデルとしてはCNNやCRNNを利用した。
従来は複数の手法を組み合わせて各楽器のアクティベーションを取得していた。現在のSOTAはEnd-to-End。ここでいうEnd-to-Endとは,スペクトログラムなどの音響特徴量から「1つの処理で」各楽器のアクティベーションを得るような技術のことを指す。アクティベーションが得られれば,ピークピッキングやベイズを用いた言語モデルを利用してオンセットを求める。 End-to-EndはNMFベースとDNNベースの手法に分類される。DNNベースの手法ではRNNやCNNが用いられる。最近ではCRNNがそれらの性能を上回ることが示唆されている。
3パート以外を扱おうとする先行研究としては,いくつかのグループに分類する研究や楽器ごとの演奏法に基づいてグループ化する研究が挙げられる。しかし,研究の総数は少なく,現在入手可能なデータセットを用いてなされた研究はない。
さらに,DNNの発展によりアノテーションデータの必要性が高まっている。しかし,音声認識などの分野と比べてADTではラベルをつける作業に手間がかかってしまう。この問題の克服のためにはData Augmentationなどが利用される。
提案法
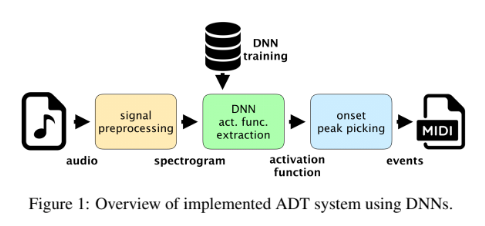
今回はマルチタスクでネットワークを学習させる。単一タスクごとに学習させると学習時間がパート数に比例して増大するから。また,NMFは基底が高次元になるにつれて精度が落ちる傾向にあるため使用しない。ネットワークの構造はCNNとCRNNを利用する。今回の場合RNNには利点がないため,使用しない。採譜は「前処理」「アクティベーション抽出」「ピークピッキング」の3ステップで行われる。
前処理では振幅ログスペクトログラムを得る。アクティベーション抽出ではCNNとCRNNを利用。両者の違いは最終レイヤーのみ。前者は全結合。後者はGRU。LSTMを使わない理由としては,GRUはLSTMに比べて訓練が簡単でありながら同程度の精度を出せることが分かっているから。CRNNではCNNで局所的な特徴量を抽出して,GRUレイヤーで中期的・長期的な時系列情報を処理する。ピークピッキングはよく利用されるシンプルな方法を利用。pythonのmadmomを利用して実装。
実験・評価
従来は3パートのみの実験・評価であったため,今回はパートのクラス分けと新たなデータセット合成が必要となる。まずはドラムパートのクラス分けを示す。
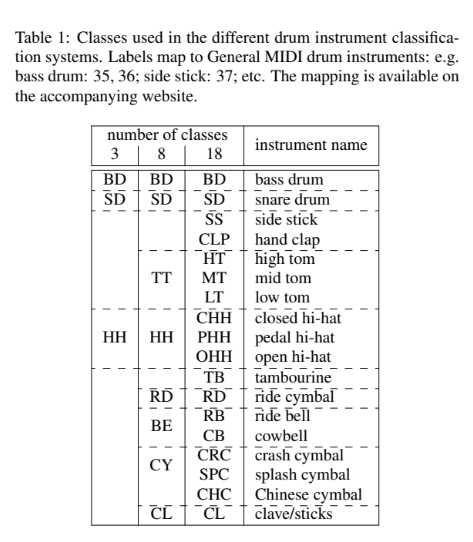
次に,簡単なデータセットのレビューをする。
・ENST:2005年発表。3人のドラマーがそれぞれ異なるドラムキットで演奏。20パートのアノテーションデータ。64トラックで計1h。
・MDB:2014年に発表されて2017年にアノテーションされた。ドラムソロで学習してmixedで評価。
・RBMA13:2017年発表。23パートとビート・ダウンビートのアノテーション付き。平均3m50sで計1h43m。
これらのデータセットの問題点は,データセットが小さすぎる点。Data Augmentationなども使われるが,オリジナルデータの質に依存する点が大きい。他にも,主要3パート以外のパートの出現頻度が低すぎて学習できないという問題もある。そこで,新たなデータセットが必要になるが,人手でアノテーションを付加するのはコストがかかってしまう。そこで,本研究では合成技術を利用してデータセットを作成する。
新たなデータセットはWeb上のフリーMIDI音源を利用。ドラムとそれ以外の楽器に分けた後,ドラムは57種類のサウンドフォントを与えられる。このサウンドフォントは様々なオンライン上で集められたもの。それ以外の楽器は通常のMIDIのサウンドフォントを使用。また,出現頻度を調整しながらサウンドフォントを18種類/8種類に分けたバージョンも作成した。このアプローチは人工的なドラムパターンを作り出してしまうリスクもあることに注意。
実験・評価
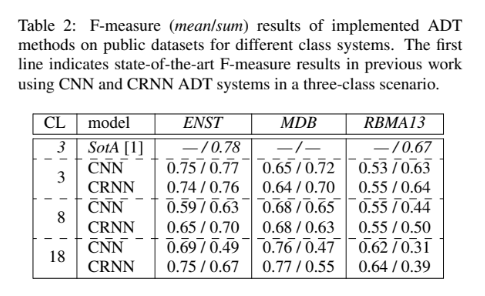
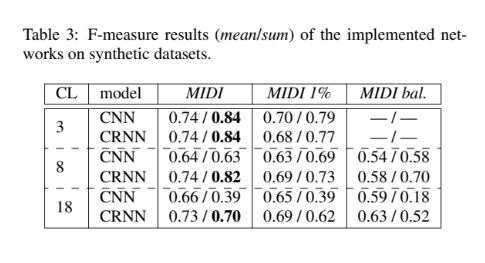
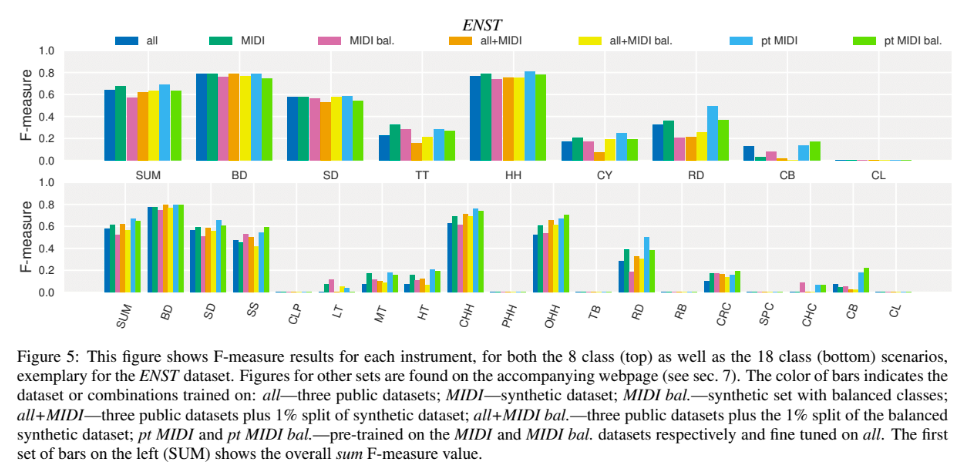
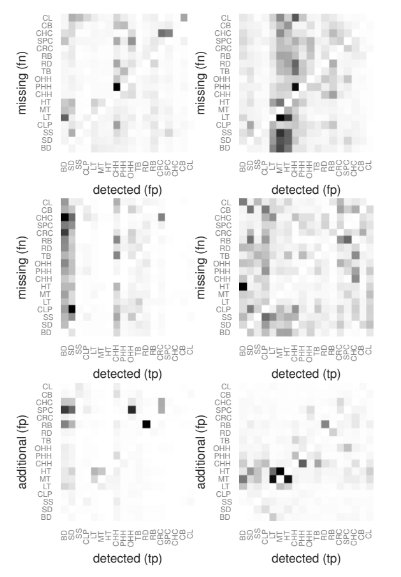
結論
実音源に対応するためには複数のパートを採譜する必要がある。本研究では,データセットの作成と合わせて複数のパートの採譜精度を比較した。エラーの種類についても考察を行なった。データセットをパートごとにバランスのとれた出現頻度とした場合,有効な場合もある一方で悪化させる可能性もあることが分かった。
まとめ
DNNを用いて複数のパートに対応しようとする研究でした。
Vogl, Richard, Gerhard Widmer, and Peter Knees. “Towards multi-instrument drum transcription.” arXiv preprint arXiv:1806.06676 (2018).











