
【超初心者向け】PythonでWebスクレイピングをする方法をやさしく解説。



今回は,Pythonでスクレイピングをする方法をお伝えしていこうと思います。プログラムを使った作業自動化の中では,メジャーな題材となっています。HTMLやCSSの知識も必要となるため,よい経験になります。
本記事はpython実践講座シリーズの内容になります。その他の記事は,以下の「Python入門講座/実践講座まとめ」をご覧ください。

スクレイピングとは
スクレイピングは,英語で「削る」という意味を表します。日本語でスクレイピングというとき,ほとんどの場合はWebスクレイピングのことを指しています。つまり,Webサイトを削っていくことで,かきくず(知りたい情報)を集める行為のことをスクレイピングと呼びます。
例えば,ニュースサイトから見出しを取ってきたり,株価の変動を調べたりするために利用されます。Webサイトに接続するため,自分のパソコンで行う際にはPythonで通信を行う必要があります。この点が,第一の関門になると思います。
スクレイピングの流れ
Pythonを利用したWebスクレイピングは,以下の流れで行います。
●HTTP通信を行う
●HTMLを取得
●欲しい情報のパスを定義
●情報抽出
それでは,実際にPythonで実装を行ってみましょう。今回の題材は「ニュースサイトから見出しを取得」「食材に含まれる栄養素を取得」としましょう。
ニュースサイトから見出しを取得
対象のサイトは「日本経済新聞」とします。一番上に表示されている記事の見出しを取得することを目標としたいと思います。
必要なライブラリ等のインポート
import requests
import urllib3
import lxml
from urllib3.exceptions import InsecureRequestWarningrequestsはHTTP通信を行うためのライブラリです。urllib3は,後ほど警告を消すために使用します。本当は警告を消すのはよくないです。lxmlはpythonでHTMLやXMLを操作するためのライブラリです。
対象のURLからResponseオブジェクトを取得
URL = "https://www.nikkei.com"
r = requests.get(URL)
requestsのgetメソッドで,Responseオブジェクトを取得できます。getメソッドはHTTP通信におけるGETと同じです。
Responseオブジェクトには,URL属性をはじめとした様々な属性が定義されています。簡単にいえば,「対象のURLに含まれている情報を一挙に集めた”モノ”」がResponsオブジェクトになります。少し,性質を調べてみましょう。
print(r)
print(type(r))
print(r.url)
print(r.status_code)
print(r.headers)
print(r.encoding)Out:
<Response [200]>
<class 'requests.models.Response'>
https://www.nikkei.com/
200
{'Content-Type': 'text/html;charset=utf-8', 'Cache-Control': 'no-cache,no-store,must-revalidate,proxy-revalidate', 'Pragma': 'no-cache', 'Content-Language': 'ja', 'Content-Encoding': 'gzip', 'Accept-Ranges': 'bytes, bytes', 'Content-Length': '45526', 'Date': 'Wed, 21 Aug 2019 07:29:23 GMT', 'Connection': 'keep-alive', 'Set-Cookie': 'KiteMigrationFlags-production=M:0,O:null,F:0; Path=/; Domain=.nikkei.com; Expires=Mon, 30 Sep 2019 15:00:00 GMT;, KiteMigrationFlags-(null)=deleted; Path=/; Domain=.nikkei.com; Expires=Thu, 01 Jan 1970 00:00:00 GMT;, KiteForce-production=0; Path=/; Domain=.nikkei.com; HttpOnly; Expires=Wed, 21 Aug 2019 19:29:22 GMT;', 'Vary': 'Accept-Encoding,X-DS-VIEW-MODE'}
utf-8urlはそのままURLのことを意味します。status_codeはHTTP通信の状態を表すコードです。200は成功を意味します。headersはレスポンスヘッダを表します。レスポンスヘッダとは,HTTP通信におけるレスポンスの一部を指しています。encodingはそのままエンコーディングの種類を示しています。
他にも,text属性とcontent属性が定義されています。text属性は,HTTPレスポンスの内容を文字列で表したものです。content属性はデコードされていないバイナリ属性を表しています。
print(r.text)Out:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" lang="ja" dir="ltr" id="R1">
<head>
<meta http-equiv="Content-Language" content="ja" />
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<meta http-equiv="Content-Style-Type" content="text/css; charset=UTF-8" />
<meta http-equiv="Content-Script-Type" content="text/javascript; charset=UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=Edge" />
<meta name="mixi-check-robots" CONTENT="nodescription, noimage">
<meta name="thumbnail" content="https://assets.nikkei.jp/release/v3.2.43/parts/ds/images/common/icon_ogpnikkei.png" />
<meta property="og:image" content="https://assets.nikkei.jp/release/v3.2.43/parts/ds/images/common/icon_ogpnikkei.png" />
<meta property="fb:app_id" content="197388106979545" />
<meta name="description" content="日本経済新聞の電子版。日経や日経BPの提供する経済、企業、国際、政治、マーケット、情報・通信、社会など各分野のニュース。ビジネス、マネー、IT、スポーツ、住宅、キャリアなどの専門情報も満載。" />
<meta name="news_keywords" content="日経,日経平均,ニュース,経済,株,新聞" />
<meta name="keywords" content="日経,日経平均,ニュース,経済,株,新聞" />
...
...
...print(r.content)Out:
b'<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">\r\n\r\n<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" lang="ja" dir="ltr" id="R1">\r\n<head>\r\n<meta http-equiv="Content-Language" content="ja" />\r\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />\r\n<meta http-equiv="Content-Style-Type" content="text/css; charset=UTF-8" />\r\n<meta http-equiv="Content-Script-Type" content="text/javascript; charset=UTF-8" />\r\n\r\n<meta http-equiv="X-UA-Compatible" content="IE=Edge" />\r\n<meta name="mixi-check-robots" CONTENT="nodescription, noimage">\r\n<meta name="thumbnail" content="https://assets.nikkei.jp/release/v3.2.43/parts/ds/images/common/icon_ogpnikkei.png" />\r\n<meta property="og:image" content="https://assets.nikkei.jp/release/v3.2.43/parts/ds/images/common/icon_ogpnikkei.png" />\r\n<meta property="fb:app_id" content="197388106979545" />\r\n<meta name="description" content="\xe6\x97\xa5\xe6\x9c\x
...
...
...
取得したテキストをHtmlElementオブジェクトに変換
root = lxml.html.fromstring(html)lxmlでHTMLを扱うときには,文字列をHtmlElementオブジェクトに変換する必要があります。fromstringは文字列からDOMツリーのルートを返します。
DOMというのは,HTMLやXMLの情報を木構造で保持しようとする概念です。fromstringを利用すれば,その木構造の根元を取得することができるのです。そして,ルートさえ定義されれば,あとは知りたい情報へのパスを設定すれば簡単に情報を抽出できます。
xpathを設定
title = root.xpath('//*[@id="JSID_baseRefreshNxTop2"]/div[1]/h3/a/span')html内の知りたい情報へのパスのことをxpathと呼びます。先ほどのルートのxpathメソッドで知りたい情報を抽出できます。xpathは,htmlの中で定義されているidからタグの階層構造を下に辿っていくことで定義されています。idを目印にして,タグを渡り歩いて情報を探していくイメージです。
ここで大活躍するのが,ブラウザの「開発者ツール」です。以下では,Chromeを使っている場合のxpathの取得方法をお伝えしていきます。OSはMacを想定しています。
「command+option+I」を押す
 日本経済新聞トップページ
日本経済新聞トップページ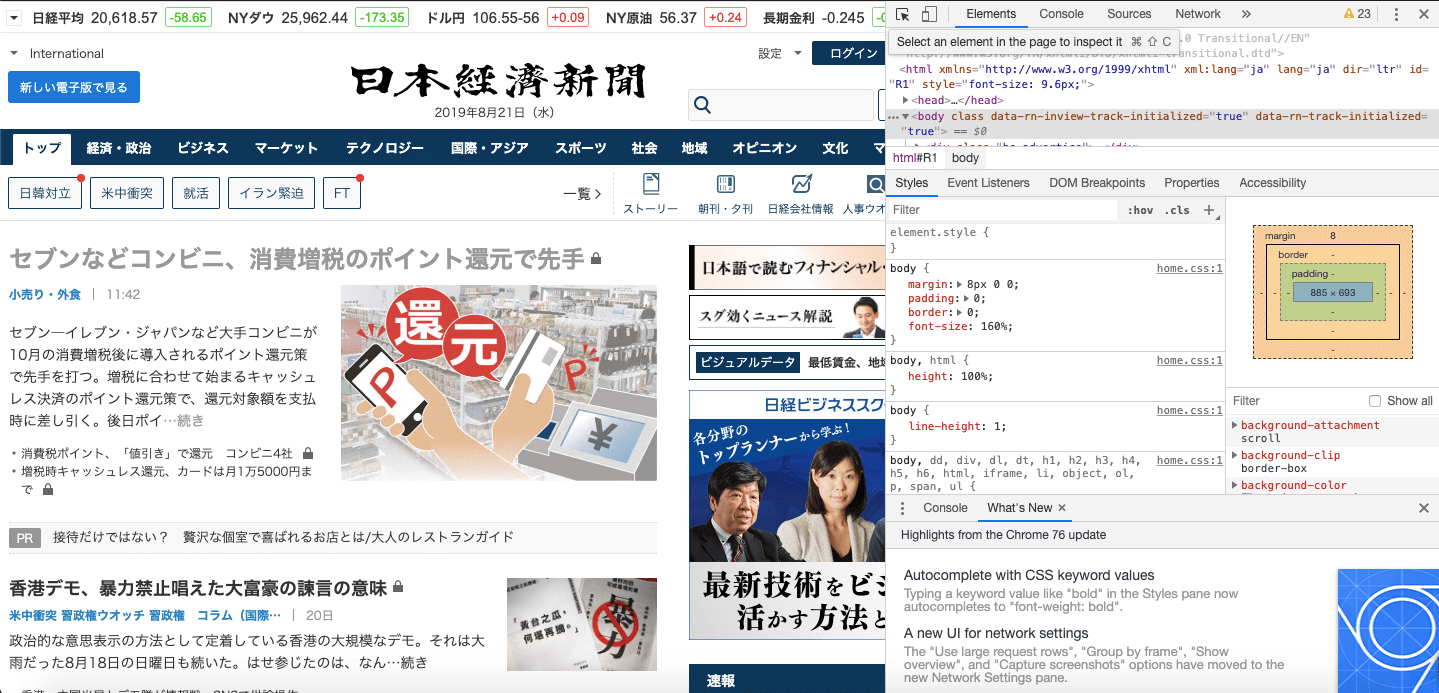 開発者ツールが開かれる
開発者ツールが開かれる選択モードにする
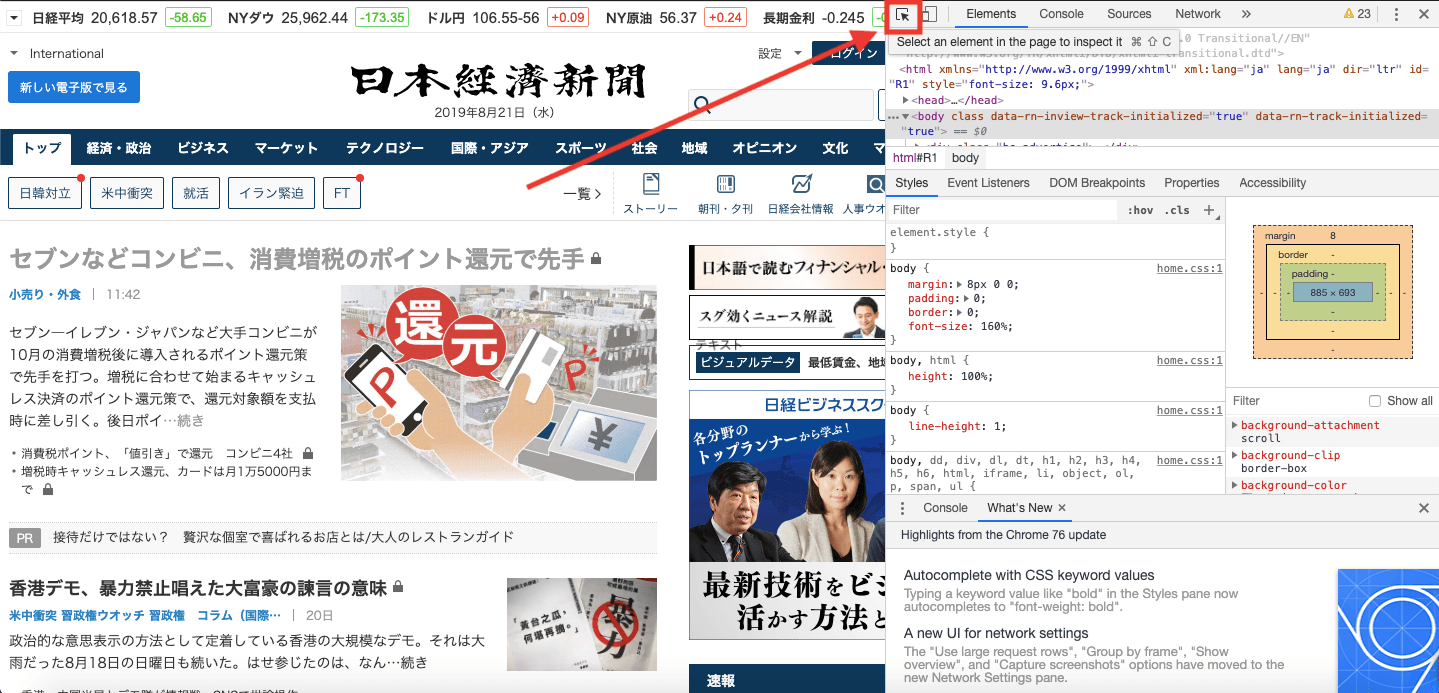 このボタンを押す
このボタンを押す知りたい情報をクリック
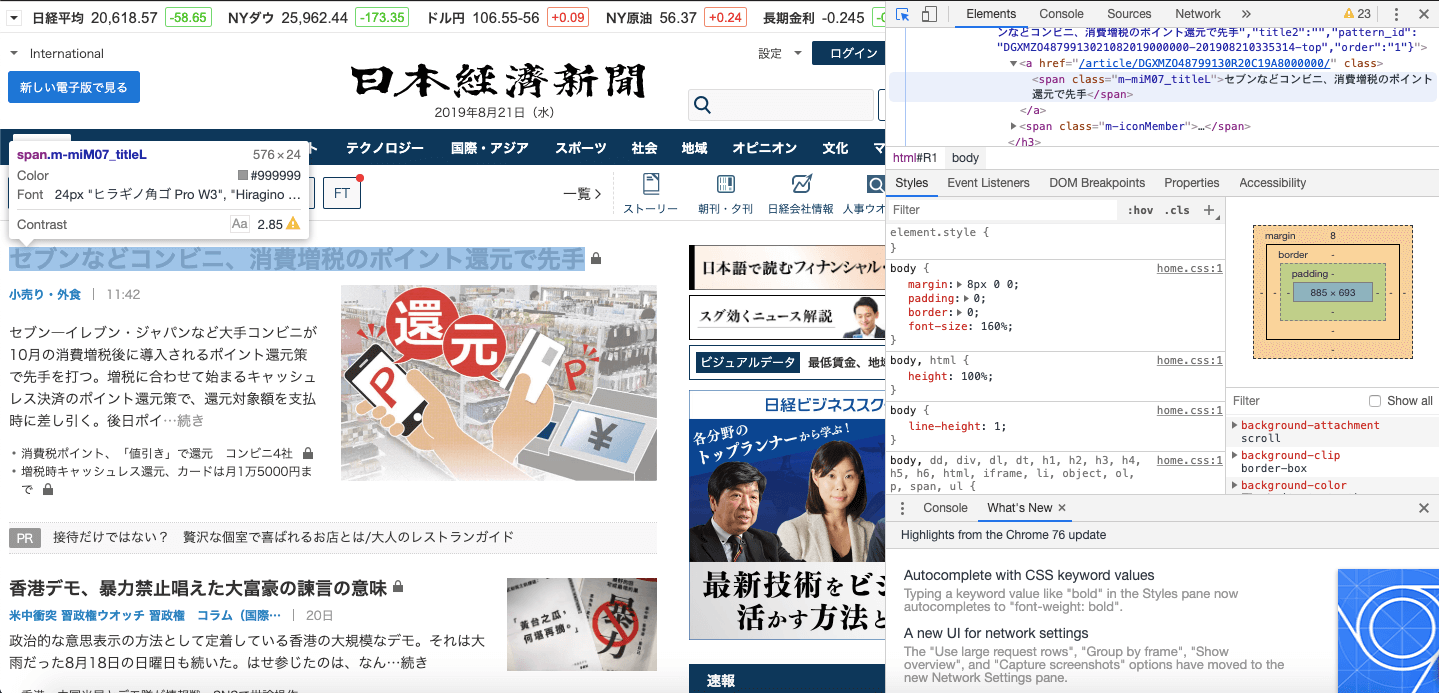 セブンなどのコンビニ…というところをクリックしています
セブンなどのコンビニ…というところをクリックしています対応する開発者ツールで網掛けになっている部分で右クリック
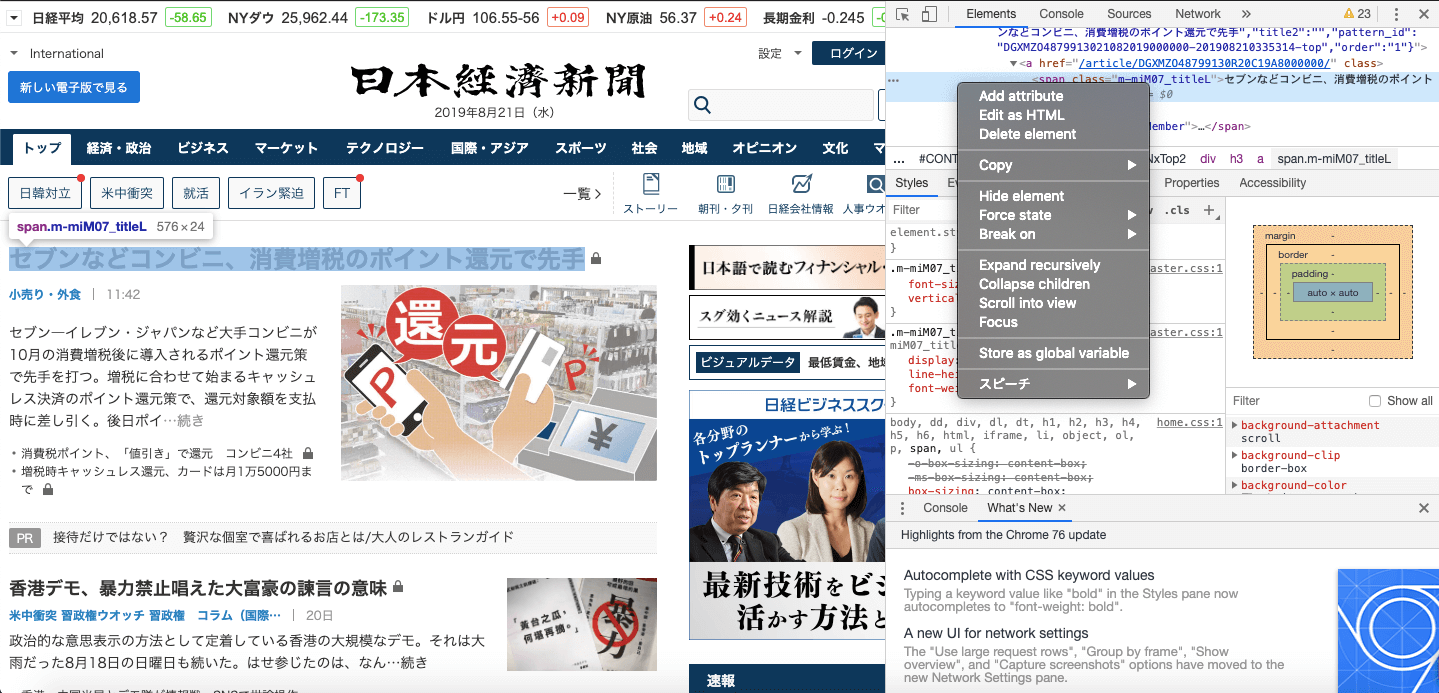 メニューが表示されます
メニューが表示されます表示されたメニューの中で「copy」を選択
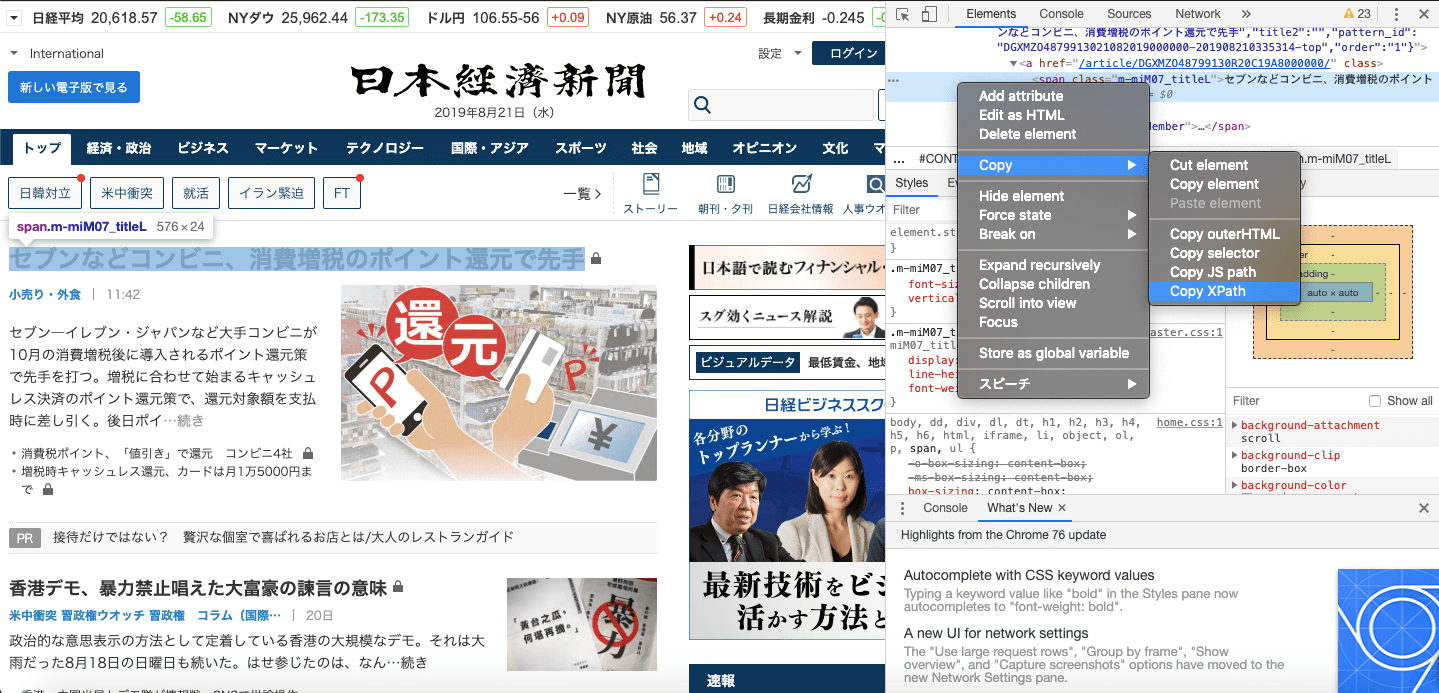 無事xpathをコピーできました
無事xpathをコピーできました
titleを表示してみる
print(title[0].text)Out:
セブンなどコンビニ、消費増税のポイント還元で先手見事,知りたい情報が手に入りました。
食材の栄養素を取得する
さて,上で学んだことを活かして食品データベースから栄養素を取得してみましょう。こちらのサイト(食品成分データベース)から,情報を抽出することにします。
必要なライブラリのインポート
import requests
import urllib3
import lxml
from urllib3.exceptions import InsecureRequestWarning先ほどとほとんど同じです。
警告をしないようにする
urllib3.disable_warnings(InsecureRequestWarning)私の環境では,食品データベースにrequests.getするときにSSLエラーが出てしまいました。そこで,(本当はよくありませんが)通信の認証をOFFにするパラメータを設定してしましました。すると,OSが警告を出してくるため,警告を無理やり非表示にするためにdisable_warningsで設定しました。
対象となる食材の定義
foods_list = ["豚肉",
"牛肉",
"鶏肉",
"卵",
"いか",
"白身魚(たら)",
"赤身魚(マグロ)",
"ヒラメ",
"たい",
"サーモン"]適当な食材を選びます。名前も適当で大丈夫です。
対応するデータベースのURLを定義
URL = ["https://fooddb.mext.go.jp/details/details.pl?ITEM_NO=11_11172_7",
"https://fooddb.mext.go.jp/details/details.pl?ITEM_NO=11_11004_7",
"https://fooddb.mext.go.jp/details/details.pl?ITEM_NO=11_11237_7",
"https://fooddb.mext.go.jp/details/details.pl?ITEM_NO=12_12004_7",
"https://fooddb.mext.go.jp/details/details.pl?ITEM_NO=10_10345_7",
"https://fooddb.mext.go.jp/details/details.pl?ITEM_NO=10_10199_7",
"https://fooddb.mext.go.jp/details/details.pl?ITEM_NO=10_10252_7",
"https://fooddb.mext.go.jp/details/details.pl?ITEM_NO=10_10234_7",
"https://fooddb.mext.go.jp/details/details.pl?ITEM_NO=10_10192_7",
"https://fooddb.mext.go.jp/details/details.pl?ITEM_NO=10_10144_7"]食品成分データベースで先ほどの対象となる商品を調べます。そのときのURLを記録していきます。
調べる栄養素の定義
vitamin_list = ["ビタミンD", "ビタミンK", "ビタミンB1", "ビタミンB2", "ナイアシン当量", "ビタミンB6", "ビタミンB12", "葉酸", "パントテン酸", "ビオチン", "ビタミンC"]今回は,栄養素の中でもビタミンに注目することにします。
xpathの定義
xpath_vitamin_d = "//*[@id='nut']/tbody/tr[30]/td[2]"
xpath_vitamin_k = "//*[@id='nut']/tbody/tr[35]/td[2]"
xpath_vitamin_b1 = "//*[@id='nut']/tbody/tr[36]/td[2]"
xpath_vitamin_b2 = "//*[@id='nut']/tbody/tr[37]/td[2]"
xpath_vitamin_ne = "//*[@id='nut']/tbody/tr[39]/td[2]" #ナイアシン当量
xpath_vitamin_b6 = "//*[@id='nut']/tbody/tr[40]/td[2]"
xpath_vitamin_b12 = "//*[@id='nut']/tbody/tr[41]/td[2]"
xpath_vitamin_fa = "//*[@id='nut']/tbody/tr[42]/td[2]" #葉酸
xpath_vitamin_pa = "//*[@id='nut']/tbody/tr[43]/td[2]" #パントテン酸
xpath_vitamin_biotin = "//*[@id='nut']/tbody/tr[44]/td[2]"
xpath_vitamin_c = "//*[@id='nut']/tbody/tr[45]/td[2]"対象となった栄養素のxpathを定義します。規則性があるので,先ほどお伝えした開発者ツールを使って簡単に調べることができます。
含まれる成分量を表示する
vitamin = {} #各食材の含有量を保持するための辞書
for i in range(len(foods_list)):
r = requests.get(URL[i], verify=False) #認証をOFFに
html = r.text
root = lxml.html.fromstring(html)
for j in range(len(xpath)):
title = root.xpath(xpath[j])
vitamin[vitamin_list[j]] = title[0].text
print('"'+str(foods_list[i])+'":'+str(vitamin)+",") #とりあえず表示するだけですOut:
"豚肉":{'ビタミンD': '1.0', 'ビタミンK': '1', 'ビタミンB1': '0.05', 'ビタミンB2': '0.12', 'ナイアシン当量': '4.1', 'ビタミンB6': '0.02', 'ビタミンB12': '0.4', '葉酸': '1', 'パントテン酸': '0.16', 'ビオチン': '-', 'ビタミンC': '0'},
"牛肉":{'ビタミンD': '0', 'ビタミンK': '7', 'ビタミンB1': '0.08', 'ビタミンB2': '0.21', 'ナイアシン当量': '7.3', 'ビタミンB6': '0.32', 'ビタミンB12': '1.5', '葉酸': '6', 'パントテン酸': '1.00', 'ビオチン': '-', 'ビタミンC': '1'},
"鶏肉":{'ビタミンD': '0', 'ビタミンK': '21', 'ビタミンB1': '0.01', 'ビタミンB2': '0.18', 'ナイアシン当量': '6.5', 'ビタミンB6': '0.08', 'ビタミンB12': '0.4', '葉酸': '7', 'パントテン酸': '0.65', 'ビオチン': '3.3', 'ビタミンC': '(0)'},
"卵":{'ビタミンD': '1.8', 'ビタミンK': '13', 'ビタミンB1': '0.06', 'ビタミンB2': '0.43', 'ナイアシン当量': '3.0', 'ビタミンB6': '0.08', 'ビタミンB12': '0.9', '葉酸': '43', 'パントテン酸': '1.45', 'ビオチン': '25.4', 'ビタミンC': '0'},
"いか":{'ビタミンD': '0.3', 'ビタミンK': '-', 'ビタミンB1': '0.07', 'ビタミンB2': '0.05', 'ナイアシン当量': '6.5', 'ビタミンB6': '0.21', 'ビタミンB12': '4.9', '葉酸': '5', 'パントテン酸': '0.34', 'ビオチン': '4.9', 'ビタミンC': '1'},
"白身魚(たら)":{'ビタミンD': '0.5', 'ビタミンK': '0', 'ビタミンB1': '0.05', 'ビタミンB2': '0.11', 'ナイアシン当量': '4.4', 'ビタミンB6': '0.09', 'ビタミンB12': '2.9', '葉酸': '12', 'パントテン酸': '0.20', 'ビオチン': '2.5', 'ビタミンC': '1'},
"赤身魚(マグロ)":{'ビタミンD': '6.0', 'ビタミンK': '(0)', 'ビタミンB1': '0.15', 'ビタミンB2': '0.09', 'ナイアシン当量': '22.0', 'ビタミンB6': '0.64', 'ビタミンB12': '5.8', '葉酸': '5', 'パントテン酸': '0.36', 'ビオチン': '1.4', 'ビタミンC': '0'},
"ヒラメ":{'ビタミンD': '3.0', 'ビタミンK': '(0)', 'ビタミンB1': '0.04', 'ビタミンB2': '0.11', 'ナイアシン当量': '8.3', 'ビタミンB6': '0.33', 'ビタミンB12': '1.0', '葉酸': '16', 'パントテン酸': '0.82', 'ビオチン': '-', 'ビタミンC': '3'},
"たい":{'ビタミンD': '5.0', 'ビタミンK': '(0)', 'ビタミンB1': '0.09', 'ビタミンB2': '0.05', 'ナイアシン当量': '9.8', 'ビタミンB6': '0.31', 'ビタミンB12': '1.2', '葉酸': '5', 'パントテン酸': '0.64', 'ビオチン': '-', 'ビタミンC': '1'},
"サーモン":{'ビタミンD': '8.3', 'ビタミンK': '6', 'ビタミンB1': '0.23', 'ビタミンB2': '0.10', 'ナイアシン当量': '11.2', 'ビタミンB6': '0.45', 'ビタミンB12': '7.2', '葉酸': '27', 'パントテン酸': '1.31', 'ビオチン': '6.3', 'ビタミンC': '2'},後のことを考えて,「”対象食品”:{ビタミン名:含有量}, 」というような表示形式をとりました。最後にコンマが付いているのは,全体を辞書型やリストなどとして定義しやすいようにするためです。
なぜ最初から全体の出力を辞書型やリストにしなかったかというと,辞書型を辞書に追加していくと,同じキーを持った辞書同士が上書き更新されてしまうためです。つまり,各食材のビタミン成分量の辞書を1つの辞書にまとめていくと,最後のサーモンの情報でいっぱいになってしまうのです。
Out:
"豚肉":{'ビタミンD': '8.3', 'ビタミンK': '6', 'ビタミンB1': '0.23', 'ビタミンB2': '0.10', 'ナイアシン当量': '11.2', 'ビタミンB6': '0.45', 'ビタミンB12': '7.2', '葉酸': '27', 'パントテン酸': '1.31', 'ビオチン': '6.3', 'ビタミンC': '2'},
"牛肉":{'ビタミンD': '8.3', 'ビタミンK': '6', 'ビタミンB1': '0.23', 'ビタミンB2': '0.10', 'ナイアシン当量': '11.2', 'ビタミンB6': '0.45', 'ビタミンB12': '7.2', '葉酸': '27', 'パントテン酸': '1.31', 'ビオチン': '6.3', 'ビタミンC': '2'},
"鶏肉":{'ビタミンD': '8.3', 'ビタミンK': '6', 'ビタミンB1': '0.23', 'ビタミンB2': '0.10', 'ナイアシン当量': '11.2', 'ビタミンB6': '0.45', 'ビタミンB12': '7.2', '葉酸': '27', 'パントテン酸': '1.31', 'ビオチン': '6.3', 'ビタミンC': '2'},
"卵":{'ビタミンD': '8.3', 'ビタミンK': '6', 'ビタミンB1': '0.23', 'ビタミンB2': '0.10', 'ナイアシン当量': '11.2', 'ビタミンB6': '0.45', 'ビタミンB12': '7.2', '葉酸': '27', 'パントテン酸': '1.31', 'ビオチン': '6.3', 'ビタミンC': '2'},
"いか":{'ビタミンD': '8.3', 'ビタミンK': '6', 'ビタミンB1': '0.23', 'ビタミンB2': '0.10', 'ナイアシン当量': '11.2', 'ビタミンB6': '0.45', 'ビタミンB12': '7.2', '葉酸': '27', 'パントテン酸': '1.31', 'ビオチン': '6.3', 'ビタミンC': '2'},
"白身魚(たら)":{'ビタミンD': '8.3', 'ビタミンK': '6', 'ビタミンB1': '0.23', 'ビタミンB2': '0.10', 'ナイアシン当量': '11.2', 'ビタミンB6': '0.45', 'ビタミンB12': '7.2', '葉酸': '27', 'パントテン酸': '1.31', 'ビオチン': '6.3', 'ビタミンC': '2'},
"赤身魚(マグロ)":{'ビタミンD': '8.3', 'ビタミンK': '6', 'ビタミンB1': '0.23', 'ビタミンB2': '0.10', 'ナイアシン当量': '11.2', 'ビタミンB6': '0.45', 'ビタミンB12': '7.2', '葉酸': '27', 'パントテン酸': '1.31', 'ビオチン': '6.3', 'ビタミンC': '2'},
"ヒラメ":{'ビタミンD': '8.3', 'ビタミンK': '6', 'ビタミンB1': '0.23', 'ビタミンB2': '0.10', 'ナイアシン当量': '11.2', 'ビタミンB6': '0.45', 'ビタミンB12': '7.2', '葉酸': '27', 'パントテン酸': '1.31', 'ビオチン': '6.3', 'ビタミンC': '2'},
"たい":{'ビタミンD': '8.3', 'ビタミンK': '6', 'ビタミンB1': '0.23', 'ビタミンB2': '0.10', 'ナイアシン当量': '11.2', 'ビタミンB6': '0.45', 'ビタミンB12': '7.2', '葉酸': '27', 'パントテン酸': '1.31', 'ビオチン': '6.3', 'ビタミンC': '2'},
"サーモン":{'ビタミンD': '8.3', 'ビタミンK': '6', 'ビタミンB1': '0.23', 'ビタミンB2': '0.10', 'ナイアシン当量': '11.2', 'ビタミンB6': '0.45', 'ビタミンB12': '7.2', '葉酸': '27', 'パントテン酸': '1.31', 'ビオチン': '6.3', 'ビタミンC': '2'},
まとめ
今回は,PythonでWebスクレイピングを行う方法を簡単にお伝えしました。URLやxpathを定義するところで,結局手間が必要になりますが,URLもxpathも階層構造を表していますので,規則性を利用すれば省力化できます。うまく,作業効率化の一環としてPythonによるスクレイピングを試していきたいところです。












