
【超初心者向け】pythonで音声認識②「音量を図示してみよう」


pythonで簡単な音声認識をやってみたいぞ。

そもそも何から始めればいいのかしら。
今回は,基本的な音声認識をpythonで行う方法をお伝えしていこうと思います。本記事はpython実践講座シリーズの内容になります。その他の記事は,こちらの「Python入門講座/実践講座まとめ」をご覧ください。

【超初心者向け】python入門講座/実践講座まとめ目次
入門講座
1.実行環境2.文字の出力3.データ型4.変数5.更新と変換6.比較演算子7.論理演算子8.条件分岐9.リスト10.辞...
スポンサーリンク
お題
音声データの音量を図示してみよう!
流れ
前回の第1回で作成したwavを読み込んで配列操作を施していきます。音量(db)の定義は以下の通りです。
\begin{eqnarray}
\rm{RMS} &=& \sqrt{\frac{1}{N}\sum_{t=0}^{N-1}x_t^2} \\
\rm{db} &=& \log_{20}\rm{RMS}
\end{eqnarray}
この定義にしたがって,配列の値を更新してしまいましょう。
必要なライブラリのインポート
import wave
import numpy as np
import matplotlib.pyplot as pltwavファイルの読み込みとnumpy化
wave_file = wave.open("[path-to-aiueo.wav]","rb") #Open
x = wave_file.readframes(wave_file.getnframes()) #frameの読み込み
x = np.frombuffer(x, dtype= "int16") #numpy.arrayに変換dbに変換する関数
def to_db(x, N):
pad = np.zeros(N//2)
pad_data = np.concatenate([pad, x, pad])
rms = np.array([np.sqrt((1/N) * (np.sum(pad_data[i:i+N]))**2) for i in range(len(x))])
return 20 * np.log10(rms)窓で区切りながらdbに変換していく点がポイントです。
実際に関数実行
N = 1024
db = to_db(x, N)今回は窓幅として1024サンプルを採用しています。1サンプルは(1/44100)[s]ですので,約0.02秒の幅で音量を算出しているということになります。
可視化
sr = 44100
t = np.arange(0, db.shape[0]/sr, 1/sr)
plt.plot(t, db, label='signal')
plt.show()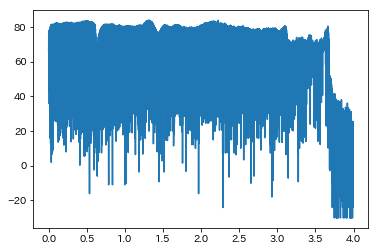
少しサンプリングが細か過ぎてよくわかりませんね。簡単な平均値によるスムージングを行ってみましょう。横軸のサンプリング数は変えないようにしてみます。(本当は横軸の細かさを変えるようなスムージングを行うべきかもです)
def smoothing(input, window):
output = []
for i in range(input.shape[0]):
if i < window:
output.append(np.mean(input[:i+window+1]))
elif i > input.shape[0] - 1 - window:
output.append(np.mean(input[i:]))
else:
output.append(np.mean(input[i-window:i+window+1]))
return np.array(output)
smoothed_db = smoothing(db, 100)
plt.plot(t, smoothed_db, label='signal')
plt.show()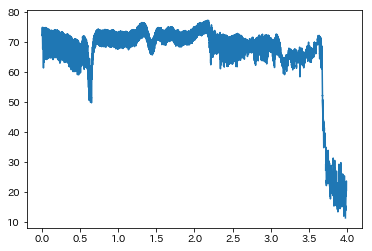
マシになりましたね。最後は無音区間が含まれていることが読み取れます。また,「あいうえお」の区切りも分かりやすいですね。












