【超初心者向け】コード認識論文要約「On the Futility of Learning Complex Frame-Level Language Models for Chord Recognition」

この記事では,研究のサーベイをまとめていきたいと思います。ただし,全ての論文が網羅されている訳ではありません。また,分かりやすいように多少意訳した部分もあります。ですので,参考程度におさめていただければ幸いです。
間違えている箇所がございましたらご指摘ください。随時更新予定です。他のサーベイまとめ記事はコチラのページをご覧ください。

【まとめページ】研究サーベイ記事一覧
和訳記事
●Attentionを用いたseq2seqのメカニズム●イラストでみるTransfomer
機械学習
基本...
スポンサーリンク
読みたい場所へジャンプ!
本論文を一枚の画像で

要旨
従来はコード認識ではHMM(First-order)ベースの言語(時間)モデルが利用されていた。最近ではRNNに基づく言語(時間)モデルが利用されるようになっている。しかし,本研究ではTime-frame単位で学習を行う言語モデルがコード認識率に寄与するのはわずかであることを示す。また,言語モデルに求められるのはより高次の遷移系列(コードの記号単位など)であることを示す。
実験1:時間モデルそのものの性能に関して

実験2:Time-frame単位の時間モデルをコードに認識に適用したときの性能に関して
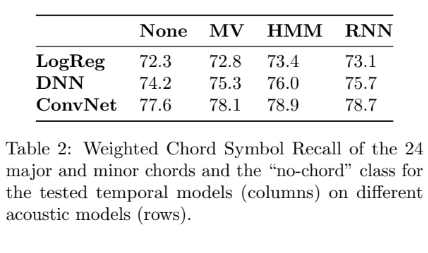
実験3:コード記号単位でモデリングした言語モデルを適用した場合の性能に関して
文章中に「Avg.Log-P. of -1.62 vs. -2.28」という記述がある。つまり,今までよりも劇的に認識性能を向上させたと言う結果になった。
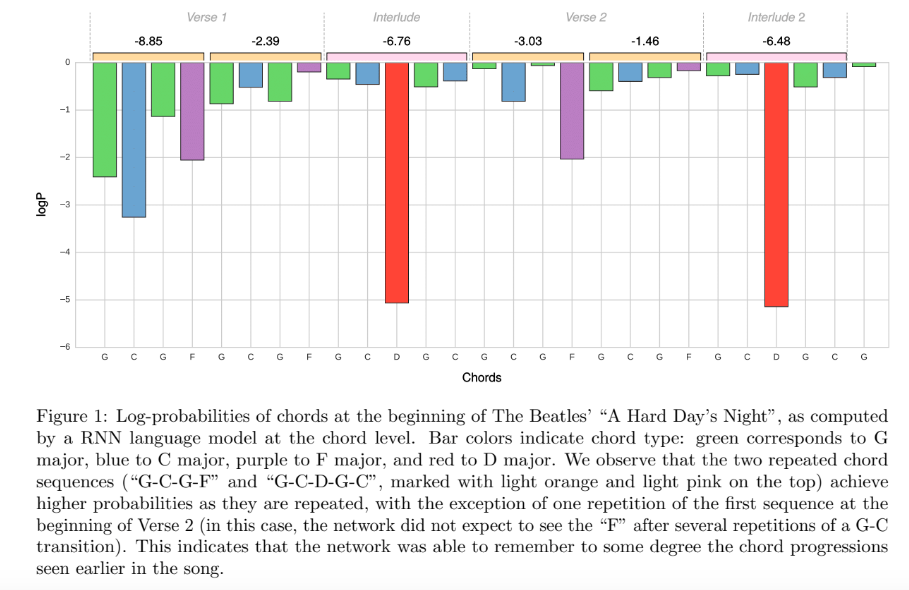
まとめ
今後はコード認識(や他のMIRのタスク)で言語モデルを扱う場合には,Time-frame単位ではなくより高次元の情報(コード記号単位など)でモデリングするべきだと主張する論文でした。
参考文献
Korzeniowski, Filip, and Gerhard Widmer. “On the futility of learning complex frame-level language models for chord recognition.” arXiv preprint arXiv:1702.00178 (2017).