【初学者向け】マルチメディア通信<新しいTCP:BBR編>

この記事では,マルチメディア通信に関わる知識を簡単にまとめていきたいと思います。ただし,全ての知識が詳しく網羅されている訳ではありません。また,分かりやすいように多少意訳した部分もあります。ですので,参考程度におさめていただければ幸いです。
間違えている箇所がございましたらご指摘ください。随時更新予定です。他のマルチメディア通信に関する記事はコチラのページをご覧ください。
HSTCP
「High-Speed TCP(超広帯域回線でのTCP)」では,従来の輻輳制御アルゴリズムに従った場合に,輻輳回避段階に時間がかかりすぎるという問題があります。

このとき,輻輳検出時に「ウィンドウサイズが大きい場合」と「輻輳ウィンドウが大きい場合」に分けて改善点が考えられます。前者はデータの送受信で利用されるウィンドウの最大値,後者はウィンドウサイズのうち実際に使用するウィンドウサイズのことを指します。
【ウィンドウサイズが大きい場合】
輻輳ウィンドウにゆとりがあるため,輻輳ウィンドウを小さくし過ぎないように1/2ではなく少しだけずらす。
【輻輳ウィンドウが大きい場合】
輻輳回復をなるべく早くアグレッシブに行いたいため,輻輳ウィンドウの増分を1セグメントずつではなく大きくする。
TCP BBR

BBR(Bottleneck Bandwidth and Round-trip propagation time)は,Googleが発表したTCP高速化のための輻輳制御アルゴリズムです。2017年には,YoutubeにBBRを適用したところ,平均で4%,国によっては14%スループットが向上したということです[参考:COMPUTERWORLD]。
従来は,パケットロスの数に基づくloss-based(ロスベース)の輻輳制御アルゴリズムが広く使われていましたが,近年のメモリの低価格化・増大の傾向に伴って,loss-basedの輻輳制御(パケットロスを検知した時のみ輻輳とする方式)では,遅延が大きすぎる状況に陥りやすいという問題点がありました。
ここでは,バッファのサイズを増大させることがTCPの高速化に繋がるという考えがベースになります。一方で,バッファのサイズを大きくすると,輻輳が発生したときに送信バッファにパケットが長い間保持され続けてしまう「Bufferbloat」という問題があります。
この問題を解決する糸口となるのが,RTT(Round Trip Time)に基づく輻輳制御アルゴリズムです。今までは,どれだけパケットがバッファから溢れ出てるかを基準にして輻輳を検知していました(loss-based)が,送受信ホスト間の往復時間であるRTTを基準にすることで,理想的にはバッファが溢れ出す前に高いスループットを実現することが可能になると考えられています。代表的なアルゴリズムは「Vegas」です。
しかし,現実では理想的な状況は起こり得ず,RTTだけでは輻輳を検知することは難しいなどという理由から,Vegasは実用化することは厳しかったようです。そこで,GoogleはRTTに加えて,データ送出量(スループット)を同時に把握・調整することで,最大のスループットを実現しようとしました。
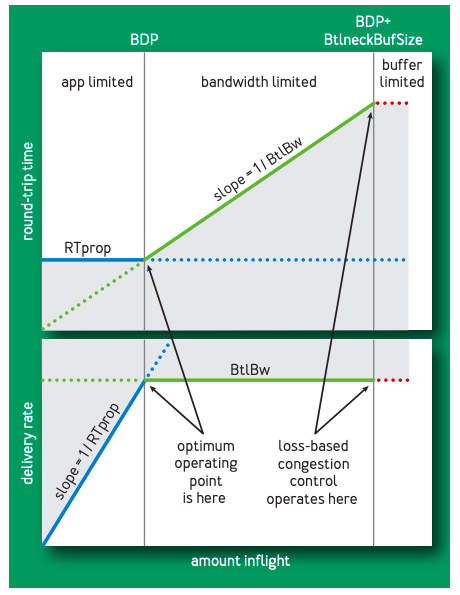
以下は,こちらの記事[外部リンク:gihyo.jp]の説明を参考にします。この図の横軸は送信中のデータ量です。縦軸の上側はRTT,下側はデータ送信量です。詳しくみていきましょう。
送信中のデータ量を増やしていくに従って,送信データ量も増大します。しかし,ある点を境にして,送信データ量は一定になります。これは,どこかのリンクでバッファが満杯になってしまったという状況を反映しています。
バッファがあふれていますので,キュー待ち(キューイング遅延)が発生し,その結果RTTが増大していきます。BBRでは,この無駄なRTTの増大を食い止めようとします。ボトルネックとなるリンクでバッファが満杯になった時点で,輻輳制御を行おうというアイディアですね。
図中の用語を用いれば,「inflight = BtlBw × RTprop」となる点で輻輳制御を行います。この点をBDP(Bandwidth-Delay Product)と呼びます。
右側に矢印で示されているポイントが「loss-based」の輻輳制御アルゴリズムにおける変化点です。BBRでは,それらよりも左側(より早く)に輻輳を検知できる変化点があることが分かります。この変化点を模式的に表したのが,以下の「水道管」によるモデル化です。模式図はこちらのサイト[外部サイト:パケットロスに基づかない新しい輻輳制御の仕組み]を参考にしました。
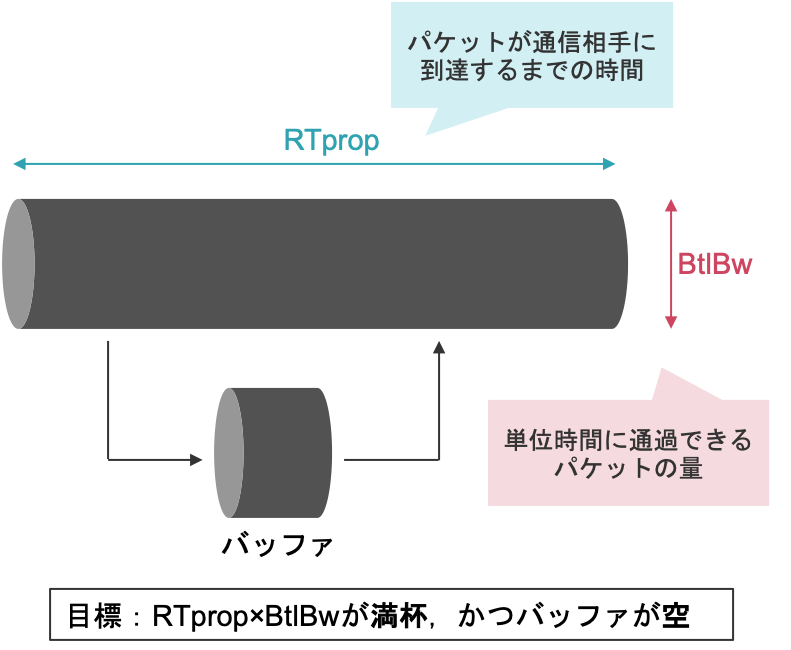
このモデルに基づいて,先ほどのグラフを見てみましょう。水道管に水を流し始めてから満杯になるまでは,水の速度は一定であるため,相手に届くまでの時間RTpropは一定です。一方で,水の総量は増えていきますので,単位時間に通過するパケットの量は増加していきます。満杯に達した時点が,この水道管を通ることができる水の総量BtlBwを表しています。
水道管が満杯になってからバッファが満杯になるまでは,水の速度は迂回路を通る分遅くなってしまうため,相手に届くまでの時間RTpropは増加していきます。一方で,水の総量はBtlBwより増えないため一定です。BBRのアイディアは,ネットワーク上で送信中のパケット量が「BtlBw × RTprop」と等しくなるように調整するというものです。
アルゴリズム詳細
以下では,こちらのサイト[外部サイト:パケットロスに基づかない新しい輻輳制御の仕組み]を参考にして,BBRの仕組みを少しだけ詳しくまとめておきます。結局,BBRではどのようにして「BtlBw × RTprop」と一致するような「inflight」を推定するのでしょうか。
RTpropに関しては,あるパケットを送信してからACK(確認応答)を受け取るまでの時間を計測します。上では,RTTとRTpropを特に区別せず説明してきました。しかし,実際には以下のように,RTTからノイズ$\eta$(受信側の都合による遅延など)を取り除いたものがRTpropです。
\begin{align}
\rm{RTT} &= \rm{RTprop} + \eta
\end{align}
ですので,実際の推定では数十秒間に渡ってRTTを計測し,その最小値を代表値として選ぶことでノイズ$\eta$を無視した$\rm{RTprop}$とします。
次に,BtlBwですが,こちらは「あるパケットを送信してからACK(確認応答)を受け取るまでの時間あたりのパケット送信量」の最大値として推定します。具体的には,あるパケットを時刻$t_0$で送信したとします。そのACKを$t_1$で受信したとします。その間のデータ送信総量の変化量を$\Delta_{0,1}$とします。BtlBwは,以下のように推定されます。ただし,肩の数字は推定の繰り返し回数のインデックスを表します。
\begin{align}
\rm{BtlBw} &= \max_{i}\;\frac{\Delta_{0,1}^{(i)}}{t_1^{(i)}-t_0^{(i)}}
\end{align}
以上のRTpropとBtlBwの推定値にしたがって,送信済みパケットのうちACK(確認応答)を受け取っていないものの総量を調整するために,パケットの送信を調整します。
実際の応用
実際のネットワークでは,複数のサーバを利用した通信を行います。ですので,複数の通信がBBRに従う必要があります(これが公平性です)。
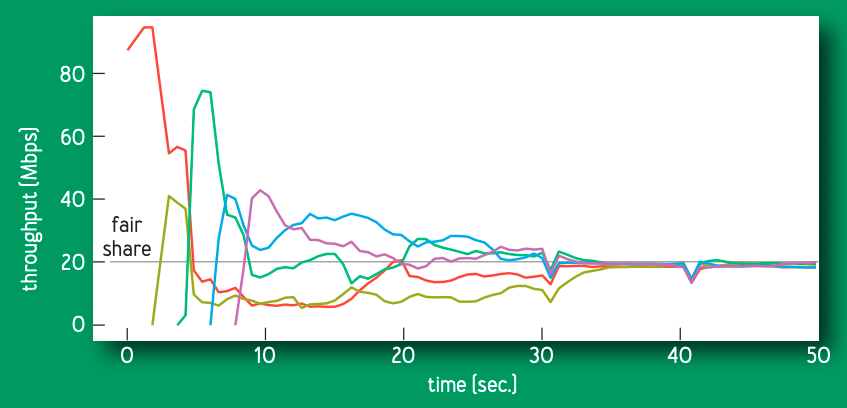
複数の通信が全てBBRに従った場合,上の図のように全てのスループットが同じ値(fair share)に収束することが確認されています。