【超初心者向け】ランク学習(LTR)とは。

この記事では,研究のサーベイをまとめていきたいと思います。ただし,全ての論文が網羅されている訳ではありません。また,分かりやすいように多少意訳した部分もあります。ですので,参考程度におさめていただければ幸いです。
間違えている箇所がございましたらご指摘ください。随時更新予定です。他のサーベイまとめ記事はコチラのページをご覧ください。
スポンサーリンク
読みたい場所へジャンプ!
ランク学習
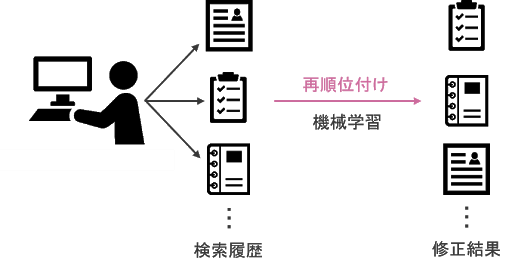 ランク学習の流れ
ランク学習の流れランク学習(Learning to rank)とは,検索結果を「ええ感じに」並び替えるための手法です。MLR(machine-learned ranking)と呼ばれることもあります。例えば,Google検索などを思い浮かべていただくと分かりやすいかと思います。単純な文字列のマッチングやせんけい線形関数を利用するだけでは,欲しい情報は手に入りにくいでしょう。
機械学習を利用して単純な検索結果をリランクすることができれば,私たちが行う「検索」という行為はより最適な形に近づいていくと思います。他にも,ユーザの位置情報や検索履歴を利用するポテンシャルも有しています。このような機械学習の概念を「ランク学習」と呼びます。
ランク学習(LTR)の流れ
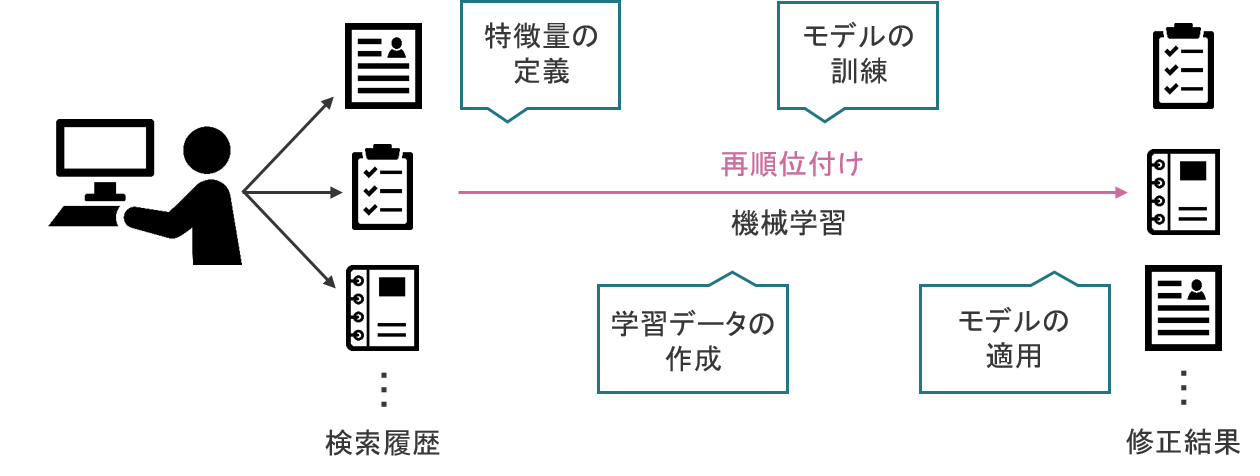 LTRの流れ
LTRの流れLTRの流れは,基本的な機械学習のフローに基づきます。つまり,何のデータに基づいてリランクを行うかを設定し(特徴量の定義),学習させるデータを作成し(学習データの作成),学習を実行し(モデルの訓練),実際の現場で応用する(モデルの適用)という全体像になっています。
特徴量の定義
- 文書の特徴量
- 単語数など
- クエリの特徴量
- 検索ワードの長さ
- 直近1週間で検索された回数
- 文書とクエリの関係性
- Okapi BM25bなどのスコア
学習方法
- Pointwise
- 正解ラベルとの二乗誤差
- 相対的な関係性を考慮できない
- Pairwise
- 文書のペアごとに損失を定義
- Listwise
- 評価スコアをそのまま損失に利用
よく利用されるモデル
- RankSVM(Pairwise)
- LTRのBaseline
- RankNet(Pairwise)
- クロスエントロピー基準のNN
- ListNet (Listwise)
- PPL(PPDのクロスエントロピー)基準
最近の動向

全文検索エンジンの「Elastic search」とランク学習を組み合わせるような提案がなされることが多いです。こちらの記事(外部リンク)などが参考になるかもしれません。簡単に,Elastic searchの特徴をまとめておきます。
- スケーラブル
- 分散・大規模活用可能
- スキーマレス
- 様々なデータ形式に対応
- マルチテナント
- 様々なサービスを横断した検索が可能
参考文献