【超初心者向け】pythonで音声認識①「録音してみよう」


pythonで簡単な音声認識をやってみたいぞ。

そもそも何から始めればいいのかしら。
今回は,基本的な音声認識をpythonで行う方法をお伝えしていこうと思います。今回は「音を録音してみよう」というお題です。本記事はpython実践講座シリーズの内容になります。その他の記事は,こちらの「Python入門講座/実践講座まとめ」をご覧ください。

【超初心者向け】python入門講座/実践講座まとめ目次
入門講座
1.実行環境2.文字の出力3.データ型4.変数5.更新と変換6.比較演算子7.論理演算子8.条件分岐9.リスト10.辞...
スポンサーリンク
お題
pythonで音を録音してwavファイルで保存してみよう!
流れ
「pyaudio」というライブラリを利用します。condaやpipなどでインストールしておいてください。
conda install pyaudioまた,以下ではこちらの記事「PythonのPyAudioで音声録音する簡単な方法[]」を参考にしながら録音を行なっていきます。
必要なライブラリのインポート
import pyaudio
import numpy as np
from matplotlib import pyplot as plt
from scipy.io.wavfile import write録音のための関数
def record(idx, sr, framesize, t):
pa = pyaudio.PyAudio() # PyAudioインスタンスの作成
data = [] # 音声データが入る入れ物
dt = 1 / sr # 1サンプルの秒数
# ストリームの開始
stream = pa.open(format=pyaudio.paInt16, channels=1, rate=sr,
input=True, input_device_index=idx, frames_per_buffer=framesize)
# フレームサイズ毎に音声を録音
for i in range(int(((t / dt) / framesize))): # t/dtでdtが繰り返される数。それをframesizeで割ることでフレーム単位の処理が何回行われるかを数えている。
frame = stream.read(framesize) # 録音を読み取る部分
data.append(frame) # 入れ物に格納する部分
# ストリームの終了
stream.stop_stream() # 然るべき回数繰り返された後は終了。
stream.close()
pa.terminate()
# フレームごとのデータをまとめる処理
data = b"".join(data)
# データをNumpy配列に変換
data = np.frombuffer(data, dtype="int16")
# pyaudio.paInt16で量子化しているため「2^(16-1)-1」で正規化している
data_show = np.frombuffer(data, dtype="int16") / float((np.power(2, 16) / 2) - 1)
return data, data_show, iここでは,正規化しない「data」と正規化した「data_show」を用意しました。というのも,正規化してしまうとこちらの公式ドキュメントに書かれている通り,wavがPCM形式出なくなってしまうため,正規化しないものをwavとして保存します。
パラメータ設定
sr = 44100 # サンプリングレート
framesize = 1024 # フレームサイズ
idx = 0 # マイクのチャンネル
t = 4 # 計測時間[s]ちなみに,マイクのチャンネルは以下のようにして確認できます。
pa = pyaudio.PyAudio()
for i in range(pa.get_device_count()):
print(pa.get_device_info_by_index(i))Output:
{'index': 0, 'structVersion': 2, 'name': 'Built-in Microphone', 'hostApi': 0, 'maxInputChannels': 2, 'maxOutputChannels': 0, 'defaultLowInputLatency': 0.0029478458049886623, 'defaultLowOutputLatency': 0.01, 'defaultHighInputLatency': 0.01310657596371882, 'defaultHighOutputLatency': 0.1, 'defaultSampleRate': 44100.0}
{'index': 1, 'structVersion': 2, 'name': 'Built-in Output', 'hostApi': 0, 'maxInputChannels': 0, 'maxOutputChannels': 2, 'defaultLowInputLatency': 0.01, 'defaultLowOutputLatency': 0.007551020408163266, 'defaultHighInputLatency': 0.1, 'defaultHighOutputLatency': 0.017709750566893424, 'defaultSampleRate': 44100.0}これを見ると「index:0」が内臓マイクロフォンということが分かります。ですので,パラメータ設定でもindexに0を指定しています。
録音の実行
data, data_show, i = record(idx, sr, framesize, t)実行した瞬間から録音が始まります。
可視化
t = np.arange(0, framesize * (i+1) * (1 / sr), 1 / sr)
plt.plot(t, wfm, label='signal')
plt.show()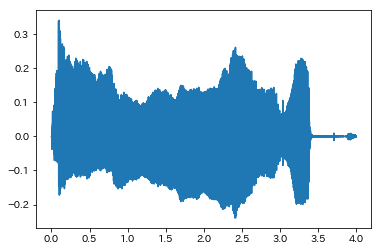
wavファイルの保存
write("/Users/zuka/Documents/class/TA/wav/aiueo.wav", sr, data)