
【超初心者向け】ドラム採譜論文要約「From Labeled to Unlabeled Data-On the Data Challenge in Automatic Drum Transcription」

この記事では,研究のサーベイをまとめていきたいと思います。ただし,全ての論文が網羅されている訳ではありません。また,分かりやすいように多少意訳した部分もあります。ですので,参考程度におさめていただければ幸いです。
間違えている箇所がございましたらご指摘ください。随時更新予定です。他のサーベイまとめ記事はコチラのページをご覧ください。

読みたい場所へジャンプ!
本論文を一枚の画像で
要旨
ADT(Automatic Drum Transcription)は急速な発展を遂げているが,データ数の不足は喫緊の問題。そこで,本論文ではラベルなしデータが学習によい影響を与えることができるかを調査した。
導入
多くの研究はENST-Drums datasetを利用していた。しかし,ラベル付きデータの少なさが問題となっていた。根拠は二つで「過学習」「評価が楽観的すぎる」。この問題意識からMDB-DrumsやRBMAのようなデータセットが作成された。本論文では「既存のデータセットの効果を調査」「他のリソースを調べたうえで既存のデータセットを助けるような技術の調査」をする。
ラベルなしデータの学習
ラベルなしデータの学習には転位学習などが用いられる。Data Augmentationは音楽に由来する手法に基づいてデータを増強する技術。しかし,両者とも走り出しには正確なラベル付きが必要。そこで,少し着眼点を変えるとラベルなしデータの有効活用が考えられる。主な教師なし学習の手法は以下の通り。
・スパースコーディング
・Deep Belief Networks
・オートエンコーダ
他に強力な手法として「知識の蒸留」と呼ばれる手法がある。この手法では学習データのラベル(Hard target)を利用しなくとも教師モデルの出力(Soft target)を利用して学習を進めることができる。知識を蒸留することで,教師モデルよりも精度が高く出る場合やモデルを軽量化することができる。
提案手法
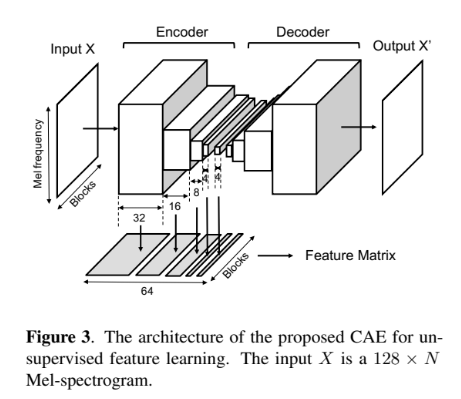
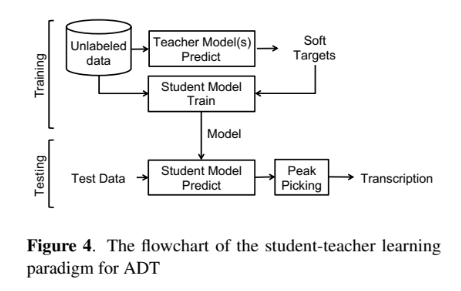
特徴量抽出はCAE。教師モデルはPFNMF,生徒モデルはDNNで作成。STFTはpythonのライブラリ「librosa」で行い,オンセット検出はpythonのライブラリMadmomから「CNNOnsetProcessor」を使用。SVMは同じくpythonのライブラリ「scikit-learn」を使用。PFNMFはNmf-DrumToolboxを使用。
実験
まずはラベル付きデータを利用してドラム採譜を試す。データセット自体の相違を確認する。
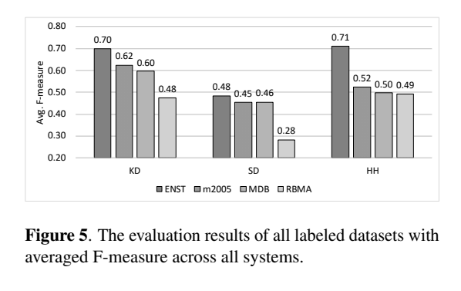
ENSTは比較的シンプルなデータセットのためF値が高く,RBMAはEDMなどのいわゆる「クラブミュージック」的なデータが含まれているためにF値は低くなったと考えられる。次に,特徴量抽出を使ってセグメント分類ベースの手法に対するラベルなしデータの有用性を測る。
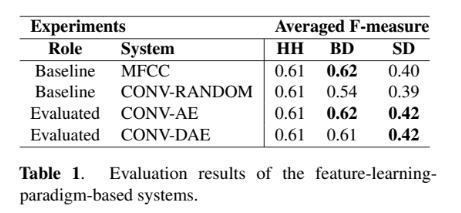
全体として特徴量抽出の有用性が確認された。さらに,知識の蒸留を使って分割検知ベースの手法に対するラベルなしデータの有用性を測る。
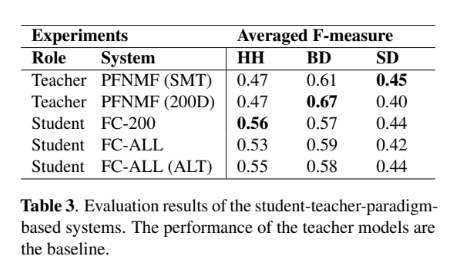
HHに対して生徒モデルの有用性が確認された。また,FC-200が他の生徒モデルの精度を上回っていることから,生徒モデルに対して多くのデータは必要でないことが示された。これは,単純な全結合ネットワークを利用しているからだろう。最後に,ラベルなしデータを利用した場合に「改善」と「悪化」を比較する。

悪化したファイル数より改善したファイル数の方が多く,F値の変化も改善したファイルの方が大きいことが分かった。また,生徒モデルに関してはアクティベーションも教師モデルよりもよりシャープになることが分かった。
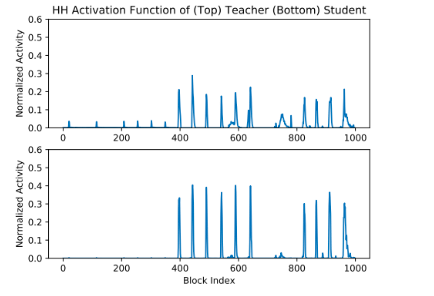
結論
ADTの評価にはより多くのデータセットが必要。特徴量抽出と知識の蒸留では,ラベルなしデータの有用性が示された。将来的にはスパースコーディングやDBNのラベルなしデータを用いた学習法の評価や教師モデル・生徒モデルの構造を変えること,異常値検出を活用する方針がある。
まとめ
ラベルなしデータをどのように活用するかを調査した論文でした。
Wu, Chih-Wei, and Alexander Lerch. “From Labeled to Unlabeled Data-On the Data Challenge in Automatic Drum Transcription.” ISMIR. 2018.











