
【超初心者向け】ドラム採譜論文要約「A Review of Automatic Drum Transcription」

この記事では,研究のサーベイをまとめていきたいと思います。ただし,全ての論文が網羅されている訳ではありません。また,分かりやすいように多少意訳した部分もあります。ですので,参考程度におさめていただければ幸いです。
間違えている箇所がございましたらご指摘ください。随時更新予定です。他のサーベイまとめ記事はコチラのページをご覧ください。

本論文を一枚の画像で
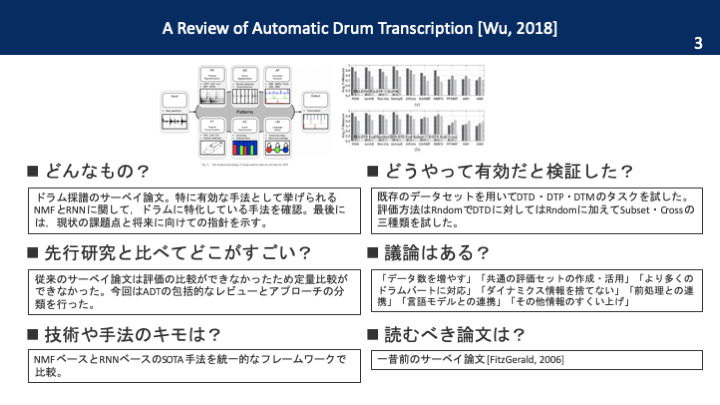
要旨
ドラム採譜のサーベイ論文。特に有効な手法として挙げられるNMFとRNNに関して,ドラムに特化している手法を確認。最後には,現状の課題点と将来に向けての指針を示す。
導入
ドラム採譜はMIR(音楽情報検索)の中でも難しいタスクの一つ。いわゆる認識系の問題であり,音楽生成とは逆のアプローチになる。ドラムは他の楽器とは少し異なる部分があり,音響イベント検知やその分類というタスクに似ている。本論文では,特に西洋音楽で利用されるドラムについて考えていく。
ドラムキット

最も基本的な構成要素は「KD」「SD」「HH」であり,ドラムキットとしては「CC」「RC」「HT」「MT」「LT」も重要。KDは低周波数成分が多く,SDは中周波数成分が多い。HHはオープトクローズで挙動が異なり,開いていると残響が残り,閉じているとすぐ減衰する。
課題と特徴
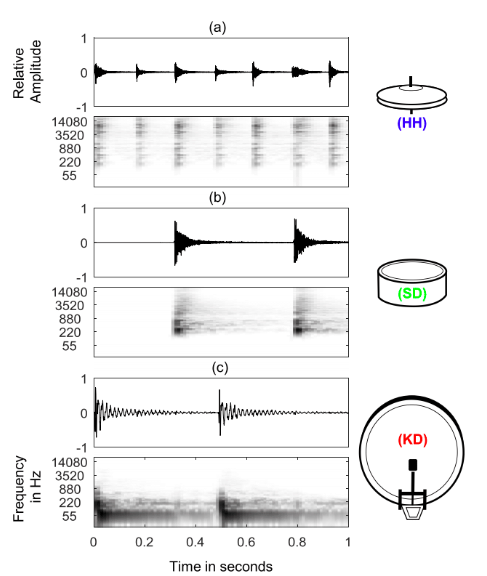
ドラムは非調波楽器であるため,調波楽器をターゲットにした手法が使えないことが多い。また,多くのパートが同時に演奏されることでスペクトログラムがオーバーラップすることがあり,認識を難しくしている。一方で,ドラムはリズムをキープする役割を持つため,基本的な繰り返し構造があることが多い。
問題設定
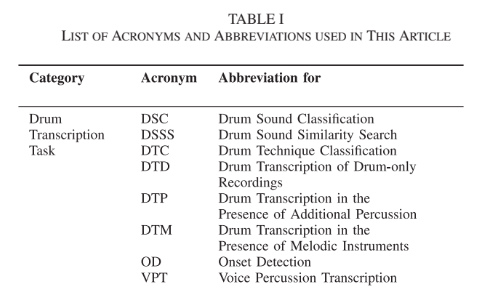
DSCはドラム音を分類するというシンプルなタスク。DSSSはその発展で,ドラム音の類似度を測るタスク。DTCは演奏テクニックを分類するタスク。DTDはドラムだけからなる音響信号を採譜するタスク。DTPは他のパーカッションもある状況下での採譜であり,同時に複数のパートが演奏されることもある。DTMはドラム採譜の究極的なタスクで,音楽音響信号からドラム譜を認識するというタスク。VPTはボイスパーカッションを採譜するタスクで,人間の声の特徴から同時に複数のパートが演奏されることはない。
ここで,ドラム採譜のアウトプットについて言及。本来であれば,採譜タスクは楽譜というシンボリックな形で出力をするべきだが,ドラムの楽器的な特徴から「ドラム音のオンセット検出と分類」のみができていればOKとする研究が多い。本論文でも,その方針に則る。
応用場面
まず,音楽教育が挙げられる。これは例えば,演奏者が譜面通りに叩けているかどうかを判定するシステムなどが考えられる。他の応用としては,作曲家支援がある。また,ドラムの再合成にも採譜システムを活用できることが示されている。また,音楽情報検索という広い視点から見れば,ドラム採譜は楽曲のリズムを推定することに寄与するだけでなく,スウィングやグルーブ感などの認識にも発展させられる。
ADTの流れ
従来のサーベイ論文では,ドラム採譜のデザインを以下の4種類に分けて捉えていた。
- Segment and Classify Approach
- Separate and Detect Approach
- Match and Adapt Approach
- HMM-based Recognition Approach
しかし,多くの手法が提案されたことにより,従来の4種類の捉え方ではドラム採譜のデザインをうまく把握することができなくなってしまった。そこで,本論文では以下のような分類で手法を概観することにする。
- Segmentation-Based Methods
- Classification-Based Methods
- Language-Model-Based Methods
- Activation-Based Methods
また,本論文では音響信号のInputからドラムパートのオンセットのOutputまでを複数のパターンの組み合わせで表現する。

FRはいわゆる特徴量抽出フェーズ。ESは音響イベントを検出するフェーズ。AFは各パートのアクティベーションを抽出するフェーズ。FTは特徴量を変換するフェーズ。ECは音響イベントを分類するフェーズ。LMは楽譜の音楽的な妥当性を測るフェーズ。以下では,本論文が提案する枠組みに沿って従来の研究を俯瞰していく。
Segmentation-Based Methods
FR・ES・ECが利用される。スペクトル包絡などの生に近い特徴量を利用する。簡単にシステムを更生することが可能である一方で,複雑なパターンや演奏テクニックに汎化性能がない欠点がある。
Classification-Based Methods
FR・ES・FT・ECが利用される。Segmentation-Based MethodsとClassification-Based Methodsは,似ているようでかなり異なる概念。前者は効率性や解釈可能性を重視。後者はパフォーマンス向上を目指す。基本的には,FRで特徴量抽出→ESで音響イベントに分割→FTで特徴量を洗練→ECでイベント分類というような流れ。FRでは古典的な特徴量からMFCC,CQTなどが利用される。FTは状況に依存するが,PCAやCFSが利用される。クラスタリングではK-meansやSVMなどが利用されてきたが,最近ではCNNなどが利用されるようになっている。様々な手法を組み合わせられる利点がある一方で,扱わなければいけないクラス数が膨大になるという欠点がある。
Language-Model-Based Methods
FR・FT・LMが利用される。HMMなどを利用して確率的に音響イベントを推定していく。確率的な枠組みで扱うことにより,音楽的に異常なパターンは排除されるようなモデル。しかし,最近LMは使われていない。理由としては,LMが発展してきた音声認識分野のものを簡単には流用できない点,音楽は音声よりも「文法」のようなものに縛られていないと考えられる点,学習データが不足している点などが挙げられる。実際に,効果が少ないことを示した研究もある。
Activation-Based Methods
FR・AF・ESが利用される。NMFが代表的な例。FRではスペクトログラムを抽出し,AFではNMFで各パートのアクティベーション行列を得る。ESではピークピッキングなどを用いてどこで鳴っているかを判別する。この手法は事前に楽器音に対応する基底行列を必要とする。最近では,DNNを使った手法が盛んに提案されている。特にRNNを使った手法はSOTAに匹敵する精度を叩き出している。振幅スペクトログラムを利用する場合は位相情報を破棄していることに注意。
データセットと評価
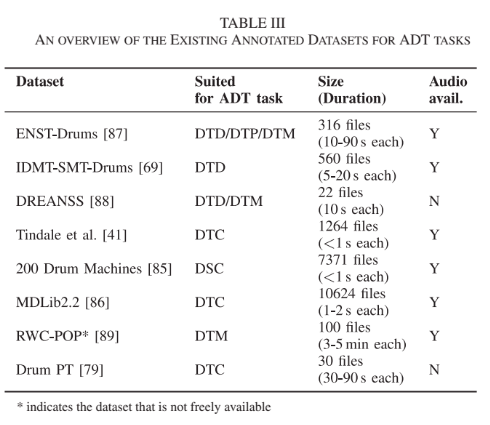
よく利用されるデータセットは上記画像の通り。主な評価方法は,クロスバリデーションを行なって精度を測るやり方。正解データに基づいてF値を計算する。許容誤差はアウトプット形式に依存するが,オンセット時刻の場合は50ms/30ms/20msなどが一般的。
現在の課題
複数の楽器の干渉
例えばドラムセットによる音の違いも精度に影響を与える。対象が音楽音響信号の場合は,KDがベースに干渉したり,SDがギターやピアノに干渉したりするため,問題として困難を極める。
演奏スキル
多くの研究では,基本的な打点のみを認識するようにしている。roll/paradiddle/drag/flam/ghost note/brush/cross stick/rimshotなどは無視されているという現状がある。このような演奏スキルを分類問題として認識しようとする試みはあったが,実際の音響にはうまく適用できないものが多かった。
録音環境
データセットの収録環境がモデルの性能に大きな影響を与える。クリーンなデータセットを利用すれば,実際の環境では応用することは難しい。
データセット不足
一番大きいのは,単位データセットのサイズが不足しているという点。ラベル付きのデータが少ない。また,従来のデータセットではドラムパターンがシンプルすぎて汎化性能を持たせることが難しくなっている。また,パターンの多様性も限られている。JPOPだけであったり,シンプルなパターンのみ収録しているものがある。また,多くの場合,収録環境が固定されていることから実環境とのギャップが大きいことも挙げられる。
SOTA手法
現在のState Of The Art手法はActivation-Based Methodsに基づきます。
NMFに基づく手法
ベースとなる素朴なNMF,基底を固定するFNMF,部分的に固定するPFNMF,それらを融合したSANMF,畳み込み積を利用したNMFDを紹介。
RNNに基づく手法
単純なRNN,双方向RNN,ラベルタイムシフトRNN,LSTM,GRUを紹介。
実験
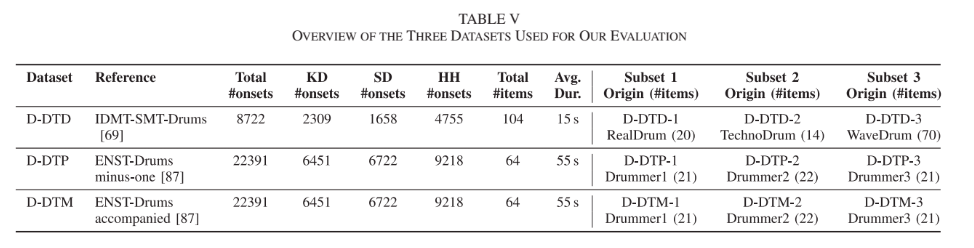
タスクはDTD・DTP・DTMとした。それぞれ既存のデータセットを利用して実験を行なった。
評価
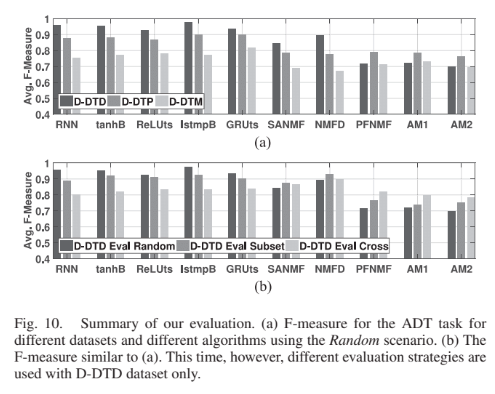
評価はデータセットを「train」「validation」「test」に分けるEval Random,サブセットで交差分割法を利用するEval Subset,異なるデータセットで評価するEval Crossの三手法を試した。基本的にはRNN系統の手法がNMFに優った。また,複雑なタスクになるほどRNNの有効性が示された。
今後の課題
データセットが多い時はRNN,少ない時はNMFというお決まりのパターン。課題としては「データ数を増やす」「共通の評価セットの作成・活用」「より多くのドラムパートに対応」「ダイナミクス情報を捨てない」「前処理との連携」「言語モデルとの連携」「その他情報のすくい上げ」の。また,データセットもマルチチャネルなどにして空間的な情報も活用できると面白い。
まとめ
非常に参考になるドラム採譜のサーベイ論文でした。
Wu, Chih-Wei, et al. “A review of automatic drum transcription.” IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP) 26.9 (2018): 1457-1483.












