【Pythonお悩み解決】スペクトログラムのサイズが想定したものと違う!
この記事は, Pythonを利用して研究を行なっていく中で私がつまずいてしまったポイントをまとめていくものです。同じような状況で苦しんでいる方々の参考になれば嬉しいです。Pythonつまずきポイント集の目次は以下のページをご覧ください。

環境
●Ubuntu 16.04
●Python 3.7.3
●conda 4.7.12
●pytorch 1.2.0
現象
スペクトログラムのサイズが想定していたものと違う。
スペクトログラムのサイズ
スペクトログラムの時間方向の大きさは窓関数のスライド幅である「hop_length」,周波数方向の大きさは窓関数の幅である「n_fft」の半分(もしくは半分+1)として決まります。
私は10msのhop_legthで時間方向の長さを揃えた上で,周波数方向に関してサイズが異なる複数のスペクトログラムを用意しました。それらのスペクトログラムのサイズを揃えるために,80ビンのメルフィルタバンクをかけて周波数方向のサイズを揃えたいと思っていました。
# ライブラリインポート
import librosa
import matplotlib.pyplot as plt
import numpy as np
# オーディオファイルの読み込み
y, sr = librosa.load("a.wav")
# 窓関数のスライド幅を10msに設定
hop_length = int(sr*0.01)
# 窓関数の幅は23ms,46ms,93msの3種類
n_fft_1 = int(sr*0.023)
n_fft_2 = int(sr*0.046)
n_fft_3 = int(sr*0.096)
# メルフィルタバンクの数は80ビン
n_mels = 80
# メルフィルタバンクにおける周波数の下限と上限
fmin = 27.5
fmax = None
# STFTの実行とデシベル変換
spec_log_1 = librosa.power_to_db(np.abs(librosa.stft(y, n_fft=n_fft_1, hop_length=hop_length, win_length=n_fft_1)))
spec_log_2 = librosa.power_to_db(np.abs(librosa.stft(y, n_fft=n_fft_2, hop_length=hop_length, win_length=n_fft_2)))
spec_log_3 = librosa.power_to_db(np.abs(librosa.stft(y, n_fft=n_fft_3, hop_length=hop_length, win_length=n_fft_3)))
# ログメルフィルタバンク処理
logmel_1 = librosa.feature.melspectrogram(sr=sr, S=spec_log, n_mels=n_mels, fmin=fmin, fmax=fmax)
logmel_2 = librosa.feature.melspectrogram(sr=sr, S=spec_log, n_mels=n_mels, fmin=fmin, fmax=fmax)
logmel_3 = librosa.feature.melspectrogram(sr=sr, S=spec_log, n_mels=n_mels, fmin=fmin, fmax=fmax)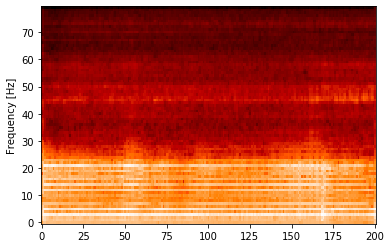
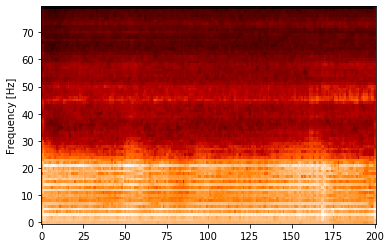
上のコードを利用すれば,確かに同じサイズのメル周波数スペクトログラムが得られます。
print(spec_log_1.shape)
print(spec_log_2.shape)
print(spec_log_3.shape)
print("----------")
print(logmel_1.shape)
print(logmel_2.shape)
print(logmel_3.shape)Out:
(254, 201)
(508, 201)
(1059, 201)
----------
(80, 201)
(80, 201)
(80, 201)窓関数の幅を変えているため,スペクトログラムの横幅は異なります。一方で,メルフィルタバンクの窓数は80にしているため,メル周波数スペクトログラムのサイズは一致しています。
ここで,私はサンプリングレートを変えて同じようなメル周波数スペクトログラムを作ろうとしました。つまり,以下のようにサンプリングレートを16000Hzにして同じ操作を行ったのです。
しかし,ここで問題が発生しました。スペクトログラムの長さが微妙に異なるのです。そこで,原因をさぐってみたところ,以下の部分に問題があるようでした。
# 窓関数のスライド幅を10msに設定
hop_length = int(sr*0.01)librosaでは,loadするときにサンプリングレートを指定しないとデフォルトで22050Hzになるように設定されています(公式ドキュメント)。ですので,上記コードを走らせると「int(220.5)=220」となり,切り捨てが行われてしまうのです。窓関数のスライド幅が正確には10msではなかったということなのです。
一方,例えばサンプリングレートに44100Hzや16000Hzを指定した場合には,「int(441.0)=441」「int(160.0)=160」となり,切り捨ては行われません。
ここの切り捨ての有無のミスマッチ(誤差)により,特に長いオーディオファイルを扱うときにスペクトログラムの時間方向の長さのズレが出てしまっていたのです。自分がこのバグに出会ったときには,特徴量の作成時点でこのようなミスをしているとは思いもよらず,1日かけてようやく切り捨てによる誤差が原因であることに気づきました。参考にしていただければ幸いです。