
【超初心者向け】コード認識論文要約「Improved chord recognition by combining duration and harmonic language models」

この記事では,研究のサーベイをまとめていきたいと思います。ただし,全ての論文が網羅されている訳ではありません。また,分かりやすいように多少意訳した部分もあります。ですので,参考程度におさめていただければ幸いです。
間違えている箇所がございましたらご指摘ください。随時更新予定です。他のサーベイまとめ記事はコチラのページをご覧ください。

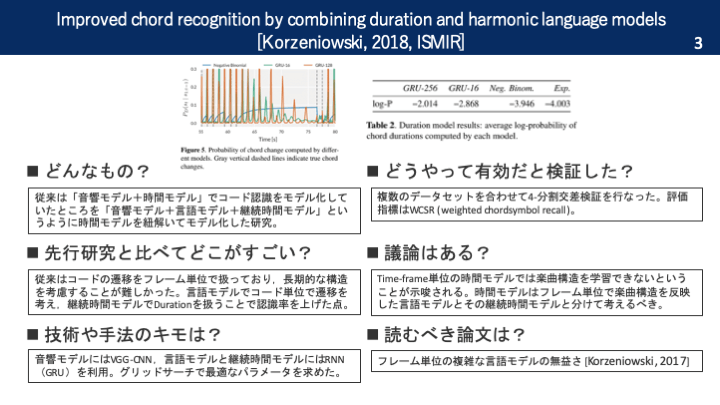
本論文を一枚の画像で
要旨
従来はコード認識のタスクは「音響モデル+時間モデル」で構成されていた。音響モデルはフレーム単位ごとの特徴量をコードに変換するタスク。時間モデルはフレーム単位で出力されるコードをそれらしく遷移させていくモデル。しかし,フレーム単位で遷移を考えている従来のシステムではコードの全体的な構成などは考慮できていなかった。そこで,本研究では「音響モデル+継続時間モデル+言語モデル」というように,時間モデルを2つのモデルに紐解くことでコード認識の精度を向上させようというアイディアを考察していく。
関連研究
従来の時間モデルは,HMMを用いて (1つ)手前のコードに基づいて次のコードを出力していた。このようなモデルは「First-orderモデル」と呼ばれている。フレーム単位のRNNでもHMMのようなFirst-orderモデルの性能を上回らないということも示されている。
時間モデルがフレーム単位でコードを認識していては,音楽の長期的な構造を考慮することは難しい。一方,時間モデルをコード列に適用できれば,コード進行を学習させることが可能になる。そこで,本研究ではフレーム単位の音響モデルとコード列単位の言語モデルを統合するための「継続時間モデル」を考案する。
提案手法
音響モデルにはVGG-CNNを利用。これはオックスフォード大学のVGGチームがか威圧したネットワークの名称で,層の深いCNNのこと。言語モデルにはRNNを利用。
実験・評価
言語モデル・継続時間モデルはグリッドサーチで最適なパラメータやモデルを調査した。
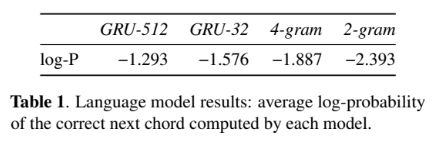

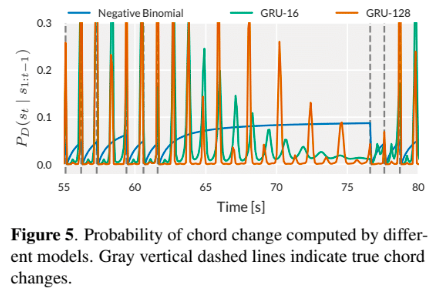

まとめ
今まで扱われなかったフレーム⇆コード系列のモデル化に注目した研究でした。
Korzeniowski, Filip, and Gerhard Widmer. “Improved chord recognition by combining duration and harmonic language models.” arXiv preprint arXiv:1808.05335 (2018).













