
【超初心者向け】コード認識論文要約「Audio Chord Recognition with a Hybrid Recurrent Neural Network」

この記事では,研究のサーベイをまとめていきたいと思います。ただし,全ての論文が網羅されている訳ではありません。また,分かりやすいように多少意訳した部分もあります。ですので,参考程度におさめていただければ幸いです。
間違えている箇所がございましたらご指摘ください。随時更新予定です。他のサーベイまとめ記事はコチラのページをご覧ください。

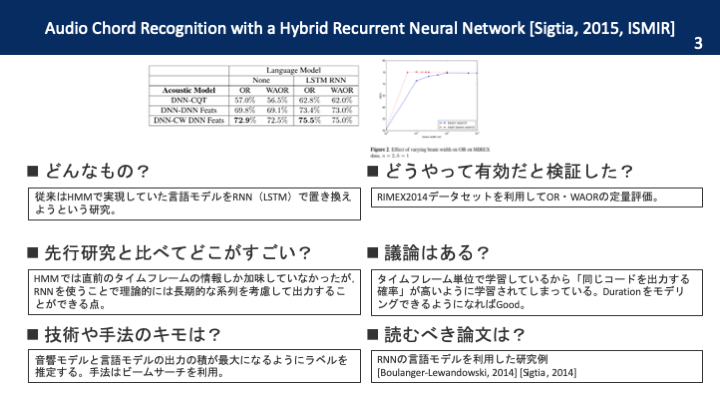
本論文を一枚の画像で
要旨
従来はHMMで時間モデル(言語モデル)を構築していたが,本研究ではRNNに置き換えるハイブリッドモデルを提案する。言い換えれば,HMMの一般化をRNNで行う。推論はビームサーチを利用して行われる。アルゴリズムもハッシュテーブルを利用して効率の良い方法を提案。結果としてSOTAを達成。
従来の問題点
RNNには「teacher forcing」と呼ばれる問題があった。これは,学習時とテスト時で異なる(学習・推論)方法を採用していることが原因であった。例えば,コード認識では学習時は各タイムステップごとに正しいラベルを出力するように学習する。一方,推論時には前のタイムステップの情報を加味しながら現在のラベルを出力する。これでは,誤差が蓄積していってしまうというのが「teacher forcing」の問題であった。
本研究では,音響モデルと時間モデルをハイブリッドさせた推論方法により,この問題を解決する。同時に,各タイムステップではほとんどの場合同じコード記号が出力されるというコード認識タスクの特性を利用して,効率的なビームサーチのアルゴリズムをハッシュテーブルを利用して提案する。
提案手法
特徴量としてはCQTまたはDNNによる特徴量抽出器を利用。音響モデルは各タイムフレームで各ラベルの出現確率をSoftmaxで計算する。言語モデルはLSTMを使用。HMMとは異なり,RNNは前の層の出力を入力として再帰的に利用するため,理論上は長い系列長を記憶できるというのがメリット。音響モデルと言語モデルは別々に訓練されて,最後にビームサーチを利用して全体の尤度が最大になるような系列ラベルが選択される。
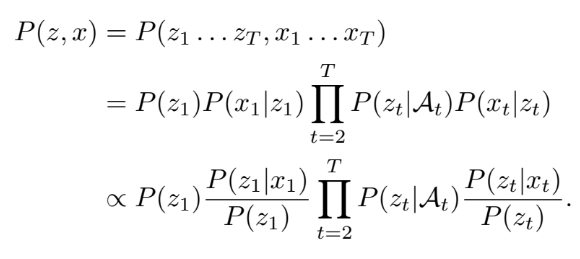
実験・評価
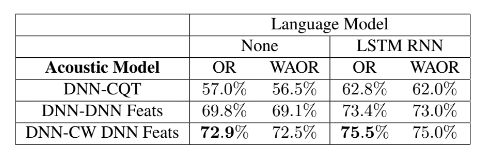
MIREX 2014で4交差分割法を使って実験を行なった。評価は「Overlap Ratio(OR)」と「weighted average overlap ratio(WAOR)」を利用。前者はコード認識のタイムフレーム単位の正解率,WAORはORを確率値で重み付けしたもの(と私は解釈しています)。
まとめ
言語モデルをRNNで実現してハイブリッドなコード認識を行おうとする研究でした。
Sigtia, Siddharth, Nicolas Boulanger-Lewandowski, and Simon Dixon. “Audio Chord Recognition with a Hybrid Recurrent Neural Network.” ISMIR. 2015.












