
【世界一分かりやすい解説】Attentionを用いたseq2seqのメカニズム

本記事は,Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)を和訳した内容になります。引用元はJay Alammarさん(@JayAlammar)が執筆されたブログ記事で,MITの授業でも実際に利用されています。
読みたい場所へジャンプ!
はじめに
Sequence-to-sequenceは深層学習で用いられるモデルの1つであり,機械翻訳や文章要約,画像キャプションの付与などの分野で大きな成功を収めています。Google翻訳では,2016年後半からこのようなモデルを使用し始めました。seq2seqモデルは,二つの先駆的な論文内で説明されています(Sutskever et al., 2014, Cho et al., 2014)。
しかし,モデルを十分に理解して実装するには,お互いの上に成り立つ一連の概念を紐解いていく必要があることが分かりました。これらのアイデアは,視覚的に表現した方がより身近なものになるのではないかと考えました。それがこの記事での狙いです。本記事を読み進めるためには,以前説明したディープラーニングの理解が必要になります。上記の論文(およびポストの後半にリンクされている注目の論文)を読むのに役立つお供になれば幸いです。
Seq2seqは,ある系列(文字列・文章列・画像の特徴量など)を受け取り,別の系列を返すモデルです。学習済みのseq2seqは,以下のように機能します。

ニューラル機械翻訳では,入力系列は次々と処理が施される一連の単語列で,出力も同様に一連の単語列です。

中身を詳しく見てみる
Seq2seqは,エンコーダとデコーダから構成されています。エンコーダは入力系列の各要素を処理し,捉えた情報を「文脈」と呼ばれるベクトルにコンパイルします。入力系列全体を処理した後に,エンコーダは「文脈」をデコーダに送り,デコーダは出力系列の各要素を次々と生成していきます。

機械翻訳の場合も同様です。
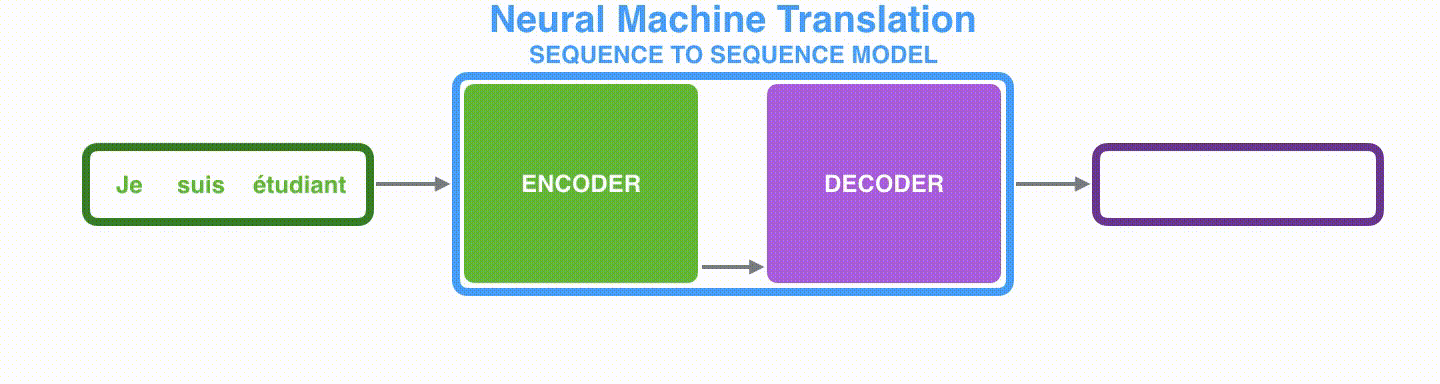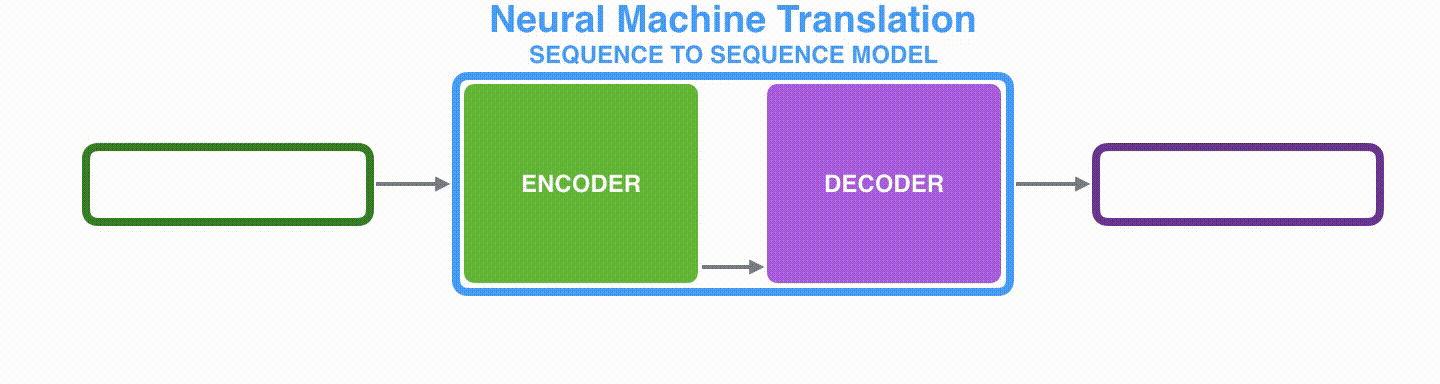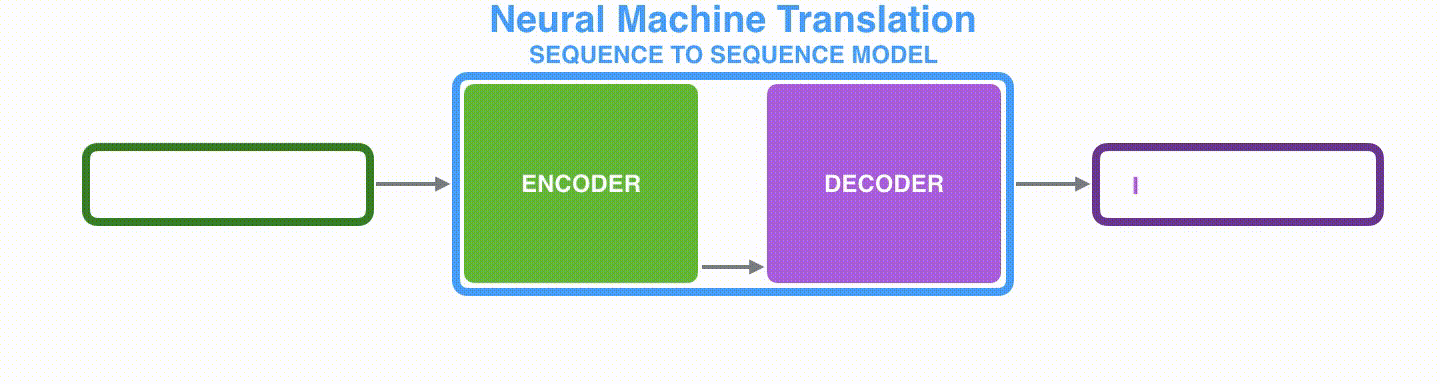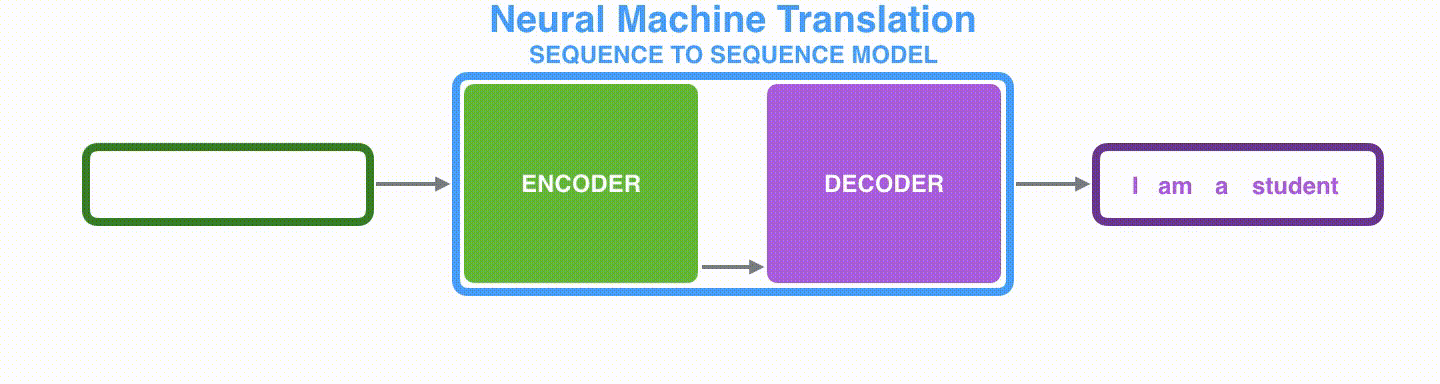
「文脈」は,機械翻訳の場合ベクトルで,基本的には数値の配列からなります。エンコーダとデコーダは,たいていの場合はRNNからなります。(RNNの入門としては A friendly introduction to Recurrent Neural Networksが参考になります)。

「文脈」ベクトルの要素は小数点で,これ以降は数字の小大を色の濃淡で表すことにします。
「文脈」ベクトルの大きさは,モデルの設計時に設定することができます。基本的には,RNNの隠れ層の次元と同じにします。上の例では4次元に設定しましたが,実際の応用では256,512,1024次元のようになります。
モデルの設計上,RNNは各タイムステップで入力と隠れ状態を受け取ります。エンコーダの場合は,入力として1つの単語を受け取ります。しかし,単語はベクトルで表す必要があります。単語をベクトルに変換するには,「単語埋め込み」と呼ばれるアルゴリズムが利用され,単語を意味情報に基づいてベクトル空間に変換します。(e.g. King-Man+Woman=Queen)
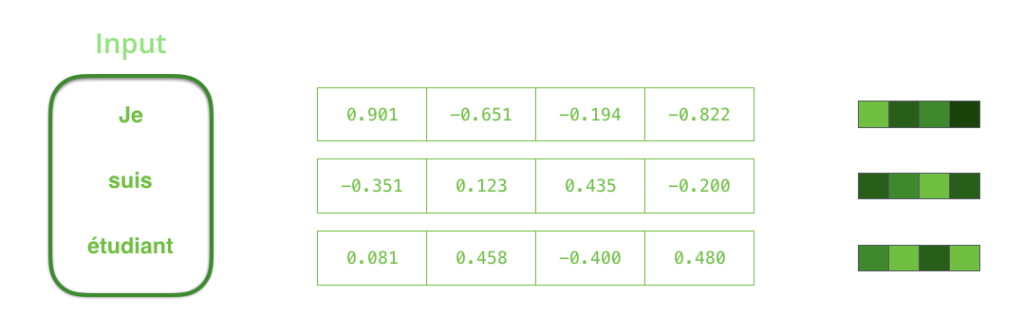
入力系列を処理する前に,単語をベクトル表現に変換する必要があります。この変換は単語埋め込みアルゴリズムを利用して行われます。事前学習済みモデルを利用することもできますし,独自に学習したモデルを利用することもできます。埋め込みベクトルの次元は200や300が一般的ですが,ここでは簡単のため4次元で表しています。
さて,ここまでは以降使用する埋め込みベクトル表現について確認してきましたが,いよいよRNNの働きを復習して可視化していこうと思います。
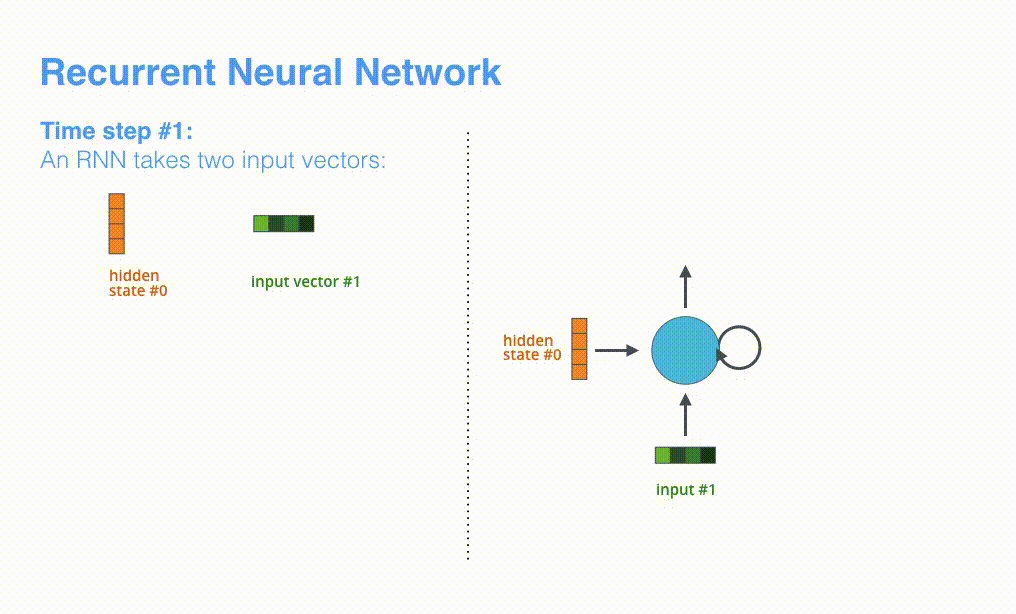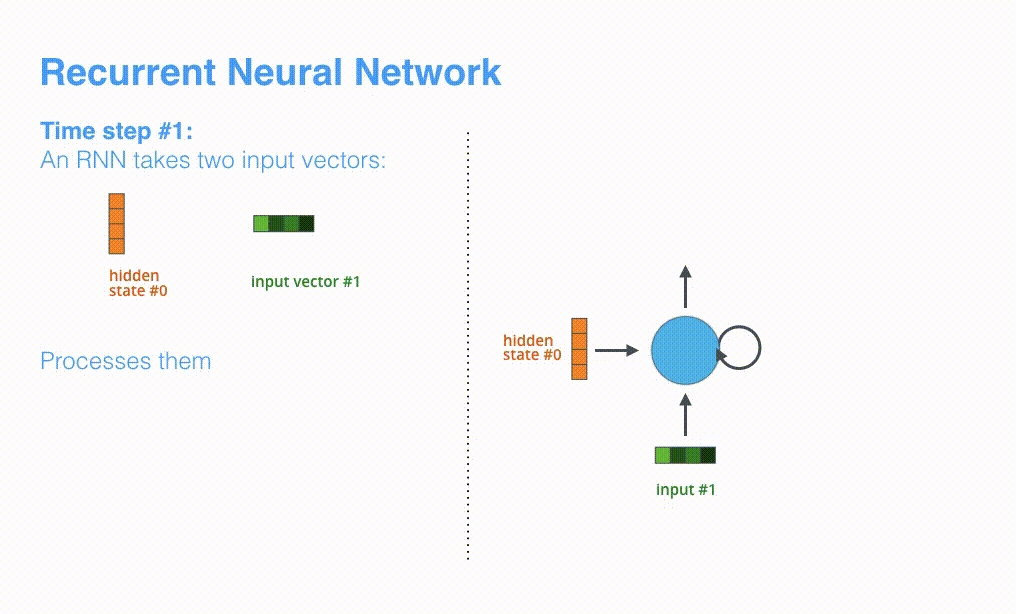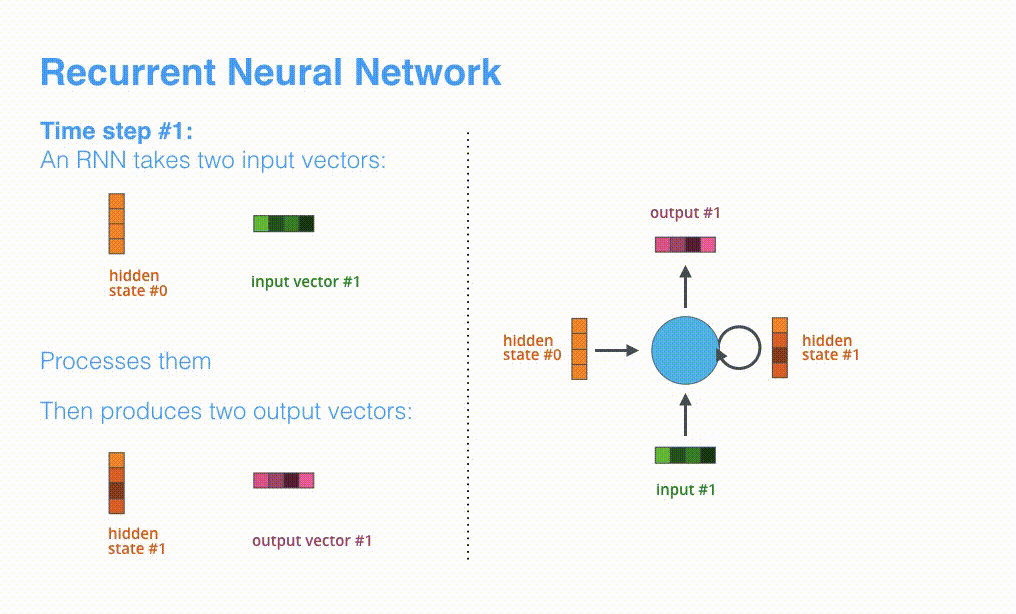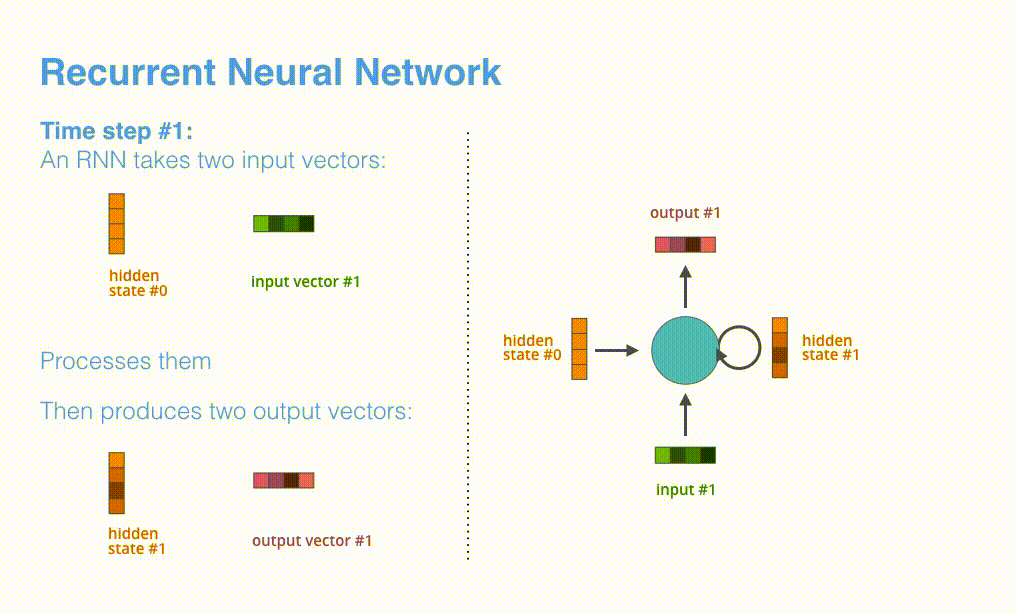
次のタイムステップでは,RNNは「input #2」と「hiden state #1」を受け取ります。この記事では,このようなアニメーションを使ってニューラル機械翻訳の内部のベクトルを表現します。
以降の可視化では,エンコーダとデコーダの振動は,RNNが入力を処理してそのタイムステップにおける出力を生成していることを表します。エンコーダとデコーダは両方ともRNNであるため,処理を行うたびに直前の出力と新しい入力に基づいて隠れ状態を更新していきます。
エンコーダの隠れ状態を見ていきましょう。エンコーダが処理した最後の隠れ状態が,「文脈」ベクトルとしてデコーダに渡されている点に注意してください。
デコーダも同様に,各時間ステップごとの隠れ状態を保持していますが,seq2seqの主要部分に注目したいために今回は省略しています。
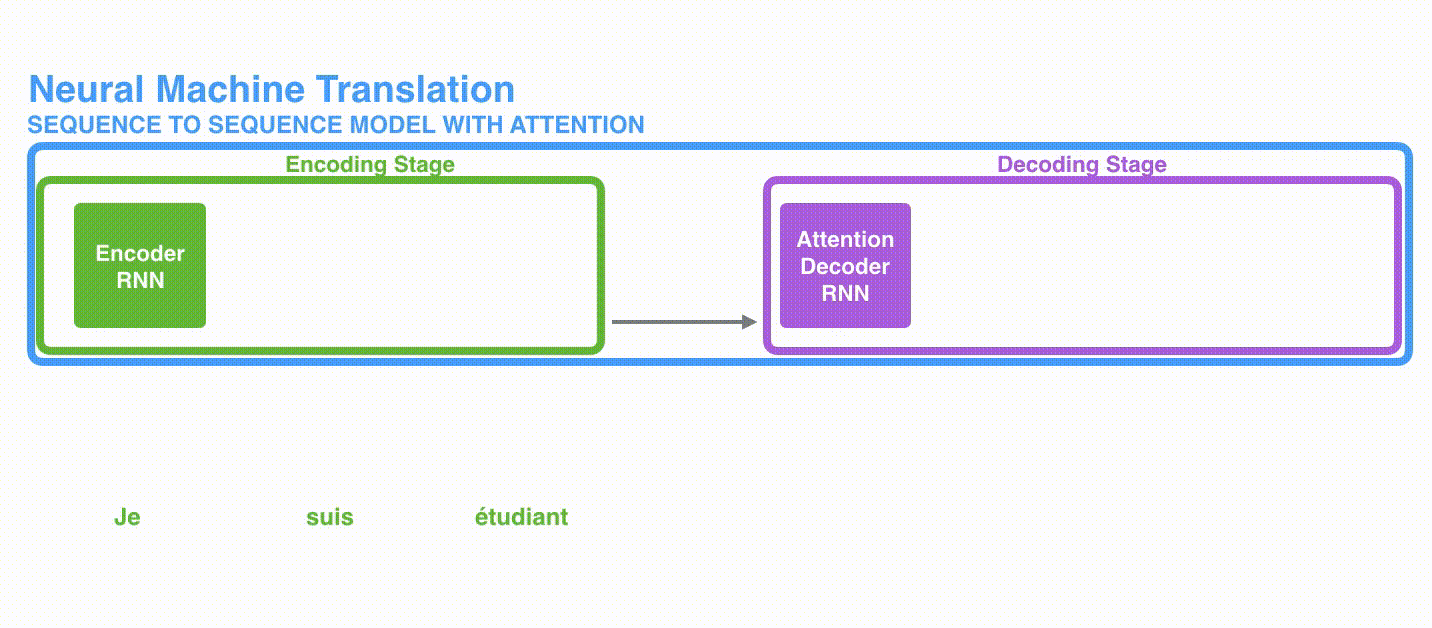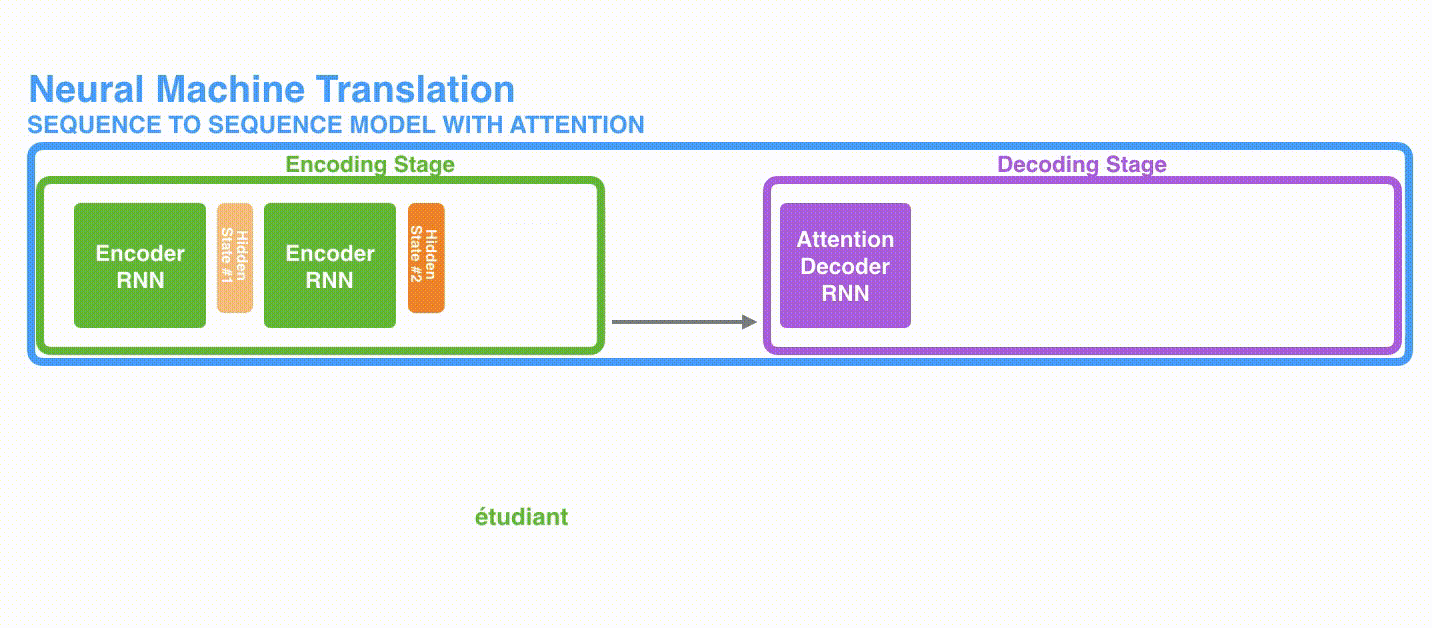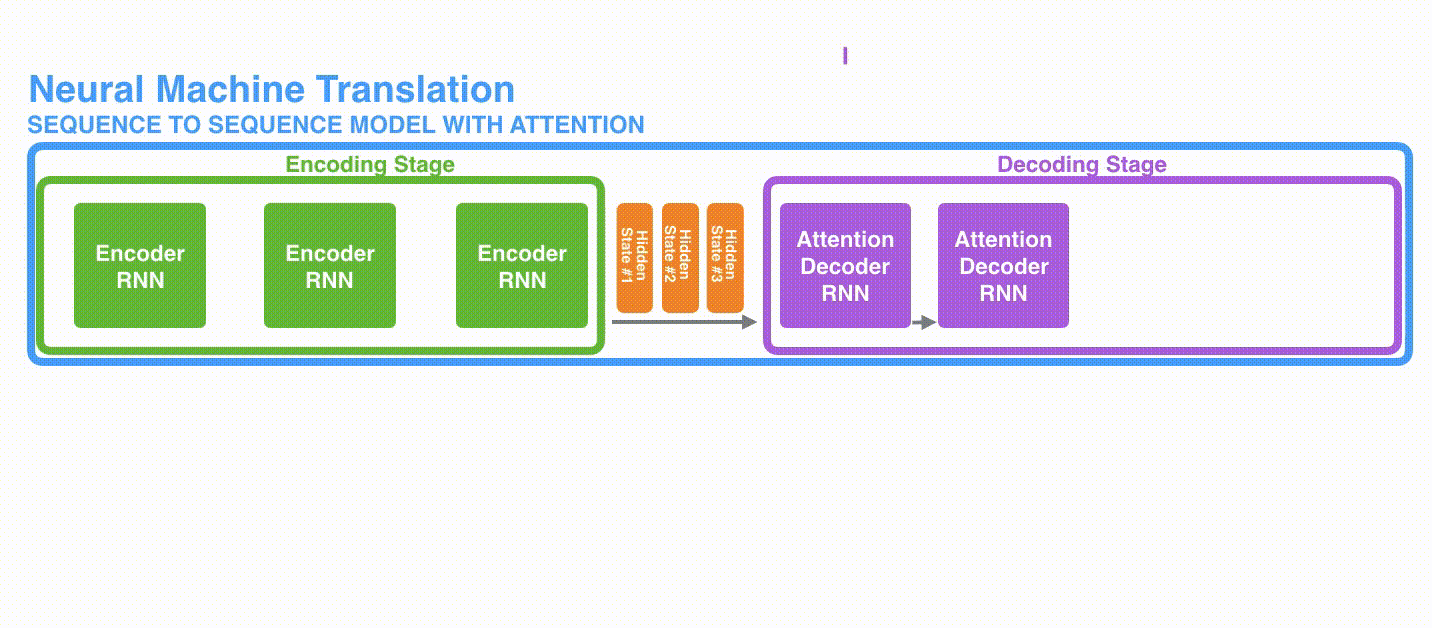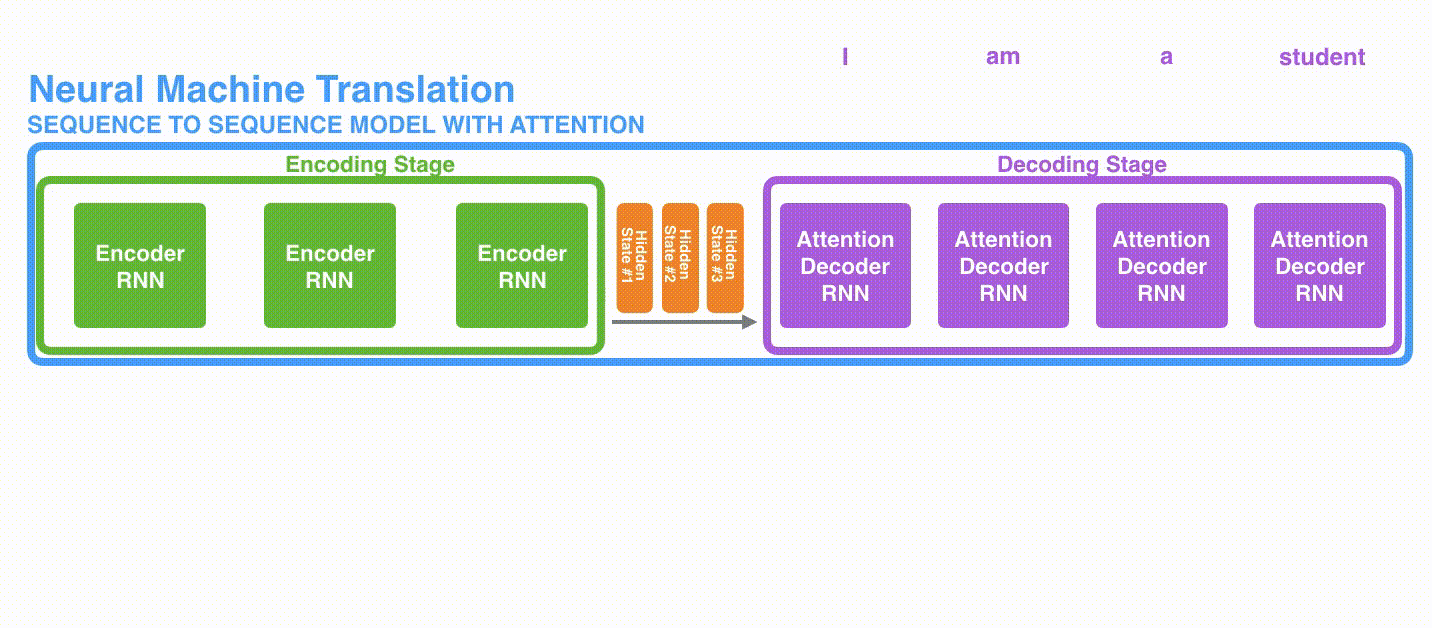
それでは,別の視点からこのモデルを眺めてみましょう。この方法は「アンロールビュー」と呼ばれるもので,アニメーションではない画像の理解をするのに役たちます。すなわち,1つのデコーダを表示する代わりに,各タイムステップごとにそのコピーを表示していきます。こうすることで,各タイムステップごとの出力を見ることができます。
さてAttentionの時間です
「文脈」ベクトルは長文を扱うことを困難にして,seq2seqモデルのボトルネックになることが判明しています。1つの解決策が Bahdanau et al., 2014とLuong et al., 2015で提案されており,Attention(注意)と呼ばれるテクニックを利用して,機械翻訳の精度を劇的に向上させました。注意機構は,入力系列の中から必要な要素に注目する方法です。
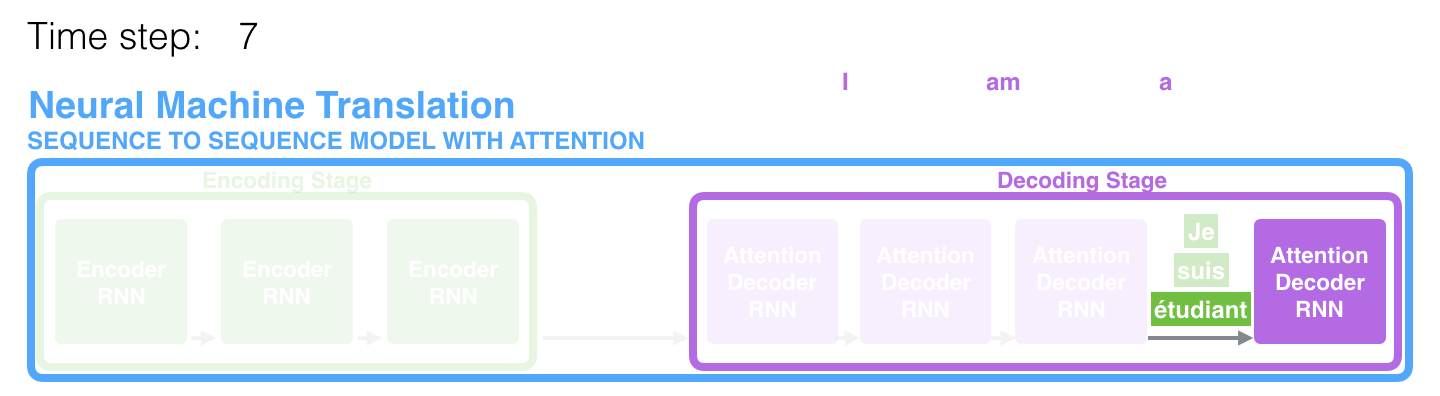
タイムステップ7では,注意機構を利用することでデコーダは英訳を生成する前に「étudiant」(フランス語では「学生」)という注目することができます。入力系列の関連要素からの情報を増幅させるしくみにより,注意機構付きのモデルは注意機構がないモデルと比べて優れた性能を発揮します。
さらに注意機構を抽象度の高いレベルで見ていきましょう。注意機構付きseq2seqモデルは,古典的なモデルと比べて以下の2点が異なります。
第1に,エンコーダはより多くの情報をデコーダに渡します。エンコーダは,最後の隠れ状態を渡す代わりに,全ての隠れ状態をデコーダに渡します。
第2に,注意機構付きのデコーダは各タイムステップに関連する入力系列の要素に注目するために,出力を生成する前に次のような処理を行います。
- 受け取ったエンコーダの全ての隠れ状態を見る。各隠れ状態は,エンコーダが処理したそれぞれの入力系列の要素に最も関連しています。
- それぞれの隠れ状態にスコアを与えます。(一旦,スコアがどのように計算されるかは無視しましょう。)
- 各隠れ状態にソフトマックスを通したスコアを乗算することで,高スコアの隠れ状態を増幅させ,低スコアの隠れ状態をかき消すことができます。
この処理は,デコーダの各タイムステップで行われます。ここで,以下に全体像を可視化して,注意機構がどのように機能するかを確認しましょう。
- デコーダのRNNは<END>トークンと隠れ状態の初期値を受け取る
- RNNは新しい隠れ状態(h4)を生成する(出力は破棄される)
- 注意ステップ:エンコーダの全ての隠れ状態とデコーダの生成した隠れ状態(h4)を利用して,各タイムステップにおける「文脈」ベクトル(C4)を生成する
- デコーダの隠れ状態(h4)と「文脈」ベクトル(C4)を結合する
- 結合されたベクトルを全結合層に通す(seq2seqモデルの内部で同時に学習させるネットワークです)
- 全結合層の出力が,各タイムステップにおける出力単語系列になります
- 以上を各タイムステップごとに繰り返す
以下のアニメーションは,デコーダの各タイムステップで入力系列のどの部分に注目しているかを見るための別の方法です。
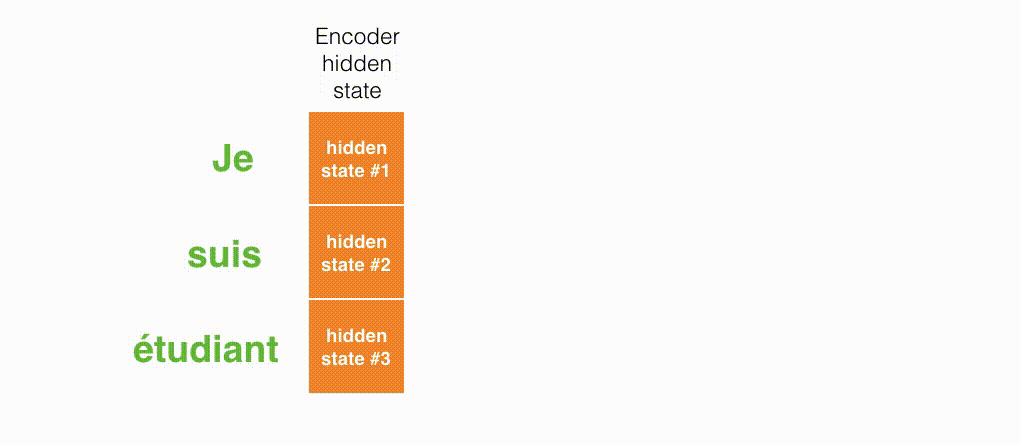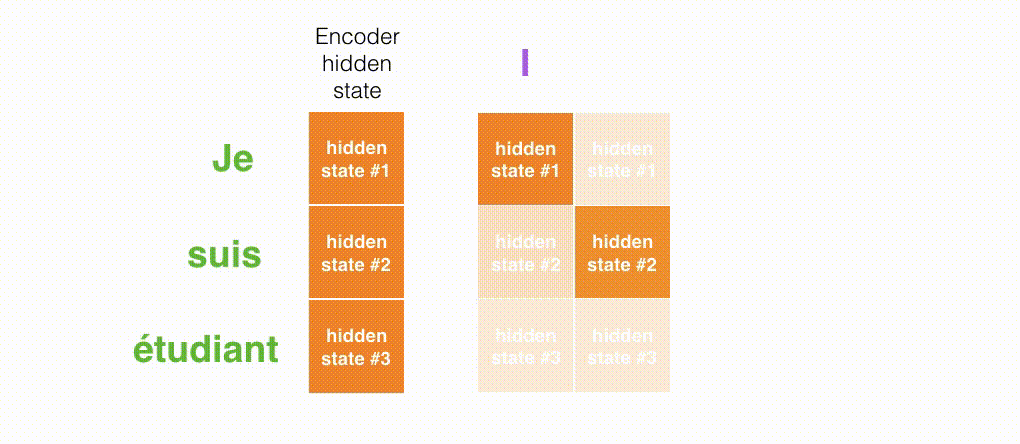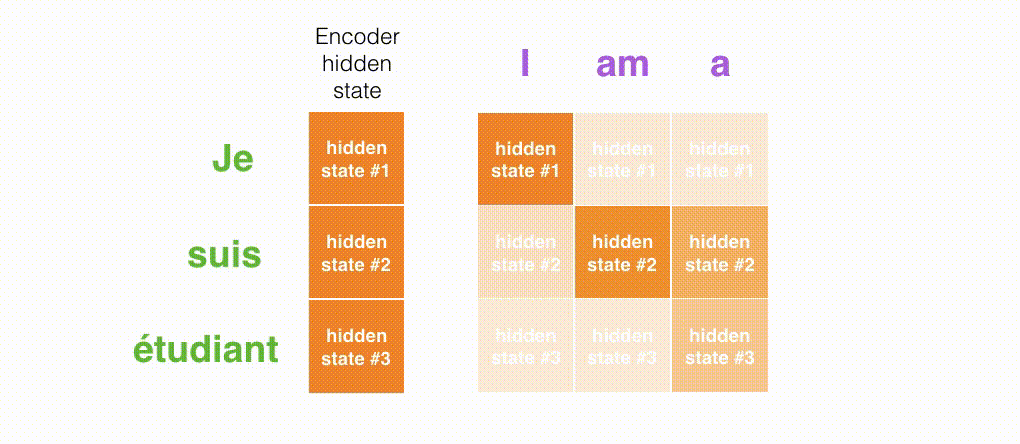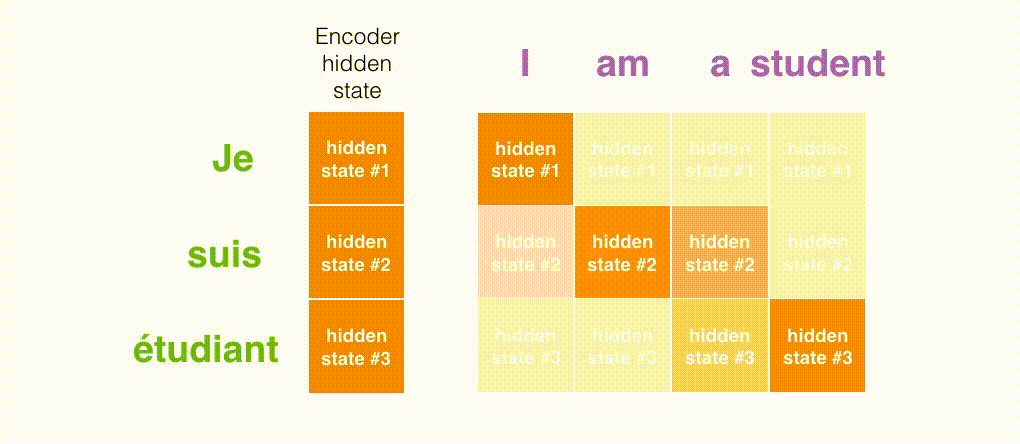
注意機構付きのモデルは,出力する最初の単語を入力系列の最初の単語に対応させている訳ではないことに注意してください。実際には,ペアデータ(この例ではフランス語と英語)の単語をどのように対応づけるかは,モデルの訓練時に学習されます。このメカニズムがどれほど正確なものであるかは,上記に挙げた論文内に具体例があります。

“European Economic Area”を出力する際に,モデルは正しく注意を払っていることが分かります。フランス語では,英語とは異なり語順が逆になっています(”européenne économique zone”)。文中の他の単語は全て同じ語順で並んでいます。
もし,読者のみなさんが実装の準備ができたと感じられるのであれば,TensorFlowのNeural Machine Translation (seq2seq) Tutorialを必ずチェックしてください。
この記事が役に立てば嬉しいです。これらの可視化は,Udacityの自然言語処理のナノ学位取得プログラムの一部で行われている注意機構についての講義のイントロです。この講義では,応用方法について議論したり,最新の手法に触れたりすることで,さらに詳しく説明していきます。
また,私は機械学習のナノ学位取得プログラムの一環として,他にいくつかの講義も作成しました。私が作成した講義は教師なし学習と,共同フィルタリングを使った映画の推薦についてのjupyterノートブックです。
皆さまからのフィードバックをお待ちしています。連絡は@JayAlammarまでお願いします。
翻訳はここまで
管理人コメント
私が思うに,世界で一番分かりやすいattentionの説明だと思っています。日本語で書かれた説明は,多くの場合静止画のみを利用しています。やはり,seq2seqを理解するためには動的な過程を踏まえることが非常に重要だと管理人自身感じています。今回は,Jay Alammarさんに許可をいただき,この素晴らしい記事を日本のみなさまに分かりやすい形で届けることを目的として翻訳致しました。ぜひ,参考にしていただければ幸いです。












ものすごく分かりやすくて感動しました。
自然言語処理に関する研究を大学で行っていて、Attentionについて何度も調べていたのですが、いまいち理解できずにいました。
ここに来て、完全に理解できました。感謝しかありません。
kazukunn様
コメントありがとうございます!
皆様のお声を励みに,これからも精進していきます。